
05.3 Redes Neuronales - Modelo MultiCapa¶
El algoritmo de retropropagación que permite entrenar una red multicapa se introduce en 1970, pero no es hasta 1986 con el artículo de Humelhart et al cuando se aprecia su potencial
import pandas as pd
from IPython import display
import numpy as np
Estructura general del modelo¶
Proceso de activación¶
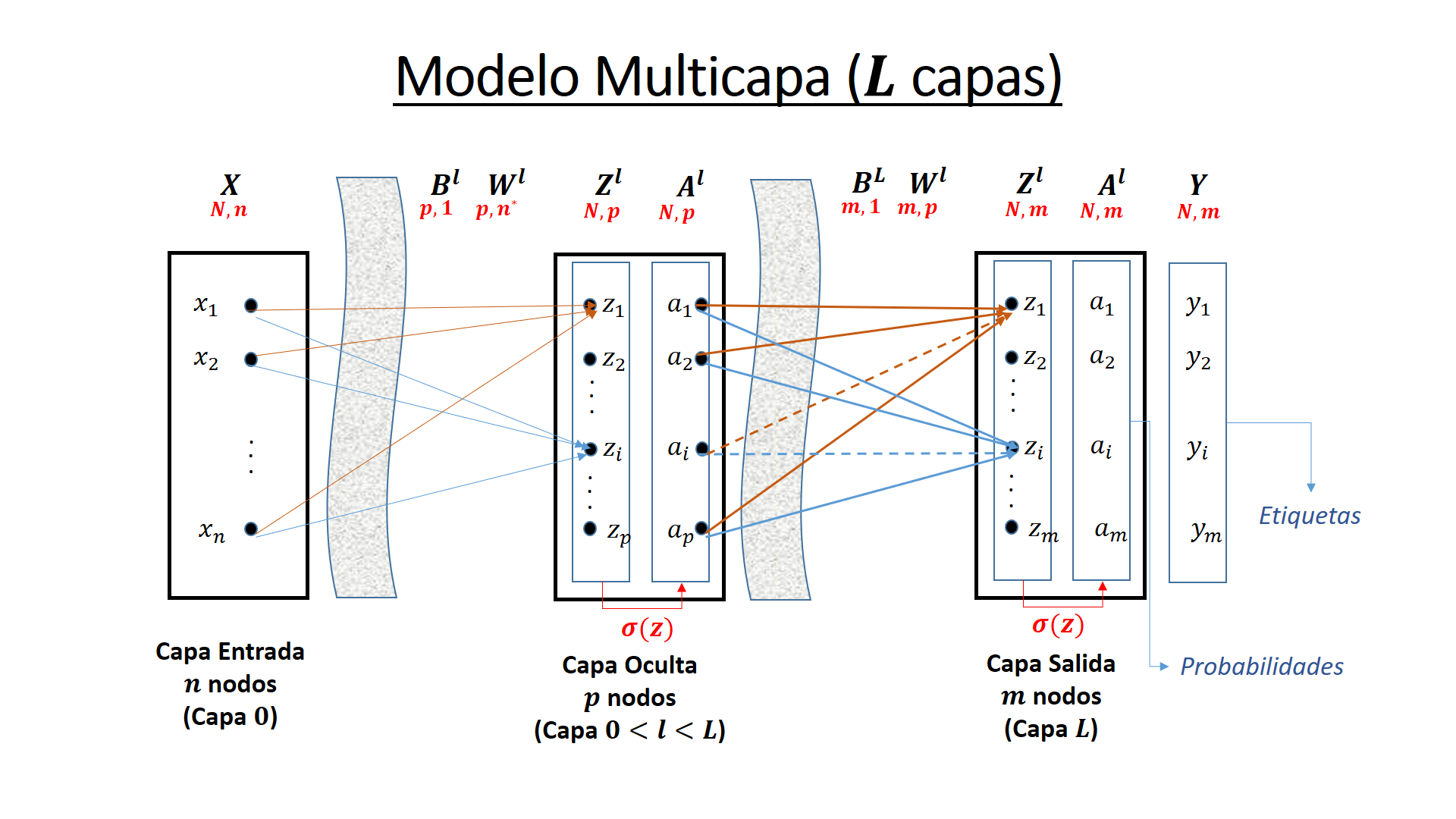
Se supone una red neuronal de \(L\) capas, sin contar la capa de entrada. Se tendrían por tanto una capa de entrada, \(L-1\) capas intermedias u ocultas y 1 de salida.
La activación de una capa intermedia \(l\) con \(l\ge L\) tiene la forma matricial
Siendo \(w^l\) la matriz de pesos que hace el sumatorio de la salida \(a^{l-1}\) de la capa \(l-1\) sobre \(l\) y \(b^l\) la matriz columna de sesgos o bias. La función \(\sigma()\) es habitualmente la función sigmoidea, pero se pueden elegir otras como la tangente hiperbólica.
Si se llama \(z^l = w^l a^{l-1} + b^l\) a la cantidad intermedia obtenida por aplicación del sumatorio. Y la activación de la capa \(l\) queda
El sumatorio en la neurona \(i\) de la capa \(l\) es igual a
Siendo \(z_i^l\) la entrada promediada a la función de activación de la neurona \(i\) de la capa \(l\)
La función de coste del error en la capa última \(L\) es
La retropropagación¶
La retropropagación (backpropagation en inglés) es comprender como cambiando los pesos y sesgos en la red cambia la función de costes, de manera que podamos iterativamente optimizar la función de costes. Implica calcular las derivadas parciales
Para llegar a este cálculo se introduce una cantidad intemedia \(\delta_j^l\) que denota el error de la neurona \(j\) de la capa \(l\). El algoritmo de retropropagación da un procedimiento para calcular el error \(\delta_j^l\) y relaciona \(\delta_j^l\) con \( \frac{\partial C}{\partial w_{jk}^l}\) y \(\frac{\partial C}{\partial b_j^l}\).
Aplicación del modelo al conjunto de entrenamiento X en bloque (proceso hacia Adelante o Forward)¶
Para la capa \(1\le l \le L\):
Siendo \(\cdot\) el producto normal de matrices y \(\oplus\) una operación “sobrecargada” que suma cada uno de los bias de la matriz \(B^1\) a una de las columnas de la otra matriz.
Si \(l=1\) entonces \(A^{l-1} = X\)
Coste del error cuadrático en la capa L¶
El error simple en la capa L es
La tasa de variación del error cuadrático por unidad de activación en la capa L (\(\Delta ^L\))
Retropropagación del error cuadrático en una capa \(1 \ge l \gt L\)¶
En la anterior ecuación se sustituye \(Y-A^L\) por la propagación del \(Delta\) existente en la capa \(l+1\)
Se empieza calculando \(\Delta ^L\) y luego se va hacia atrás, desde \(l=L-1\) hasta \(1\) calculando \(\Delta^l\), lo que se denomina retropropagación del error cuadrático por unidad de activación
El entrenamiento capa a capa queda¶
Si \(l=1\)
La clase NeuralNetwork donde se ha implementado una maqueta con el código indicado se encuentra en el archivo 05.0_RNN_Redes_Neuronales_Utilidades.ipynb
Disclaimer: El código de NeuralNetwork se incluye sólo a efectos de explicar mejor el algoritmo. No entra en examen
run 05.0_RNN_Utilidades.ipynb
<Figure size 432x288 with 0 Axes>
El Perceptron Multicapa de la librería sk-learn¶
https://scikit-learn.org/stable/modules/generated/sklearn.neural_network.MLPClassifier.html
El perceptrón multicapa está implementado en la librería sk-learn en la clase MLPClassifier de neural_network
Los parámetros de entrada más importantes son:
hidden_layer_sizes : Es una tupla con la longitud de las capas ocultas (la longitud de la tupla será = n_layers - 2). Por defecto adopta el valor (100,)
activation : funciones de activación soportadas {‘identity’, ‘logistic’, ‘tanh’, ‘relu’}, por defecto se usa ’relu’. La identidad (\(f(x)=x\)) se utiliza para probar el cuello de botella en la compresión de las capas profundas. Las sucesivas capas profundas comprimen la información para quedarse con la parte relevante de la información que soporta la clasificación.
solver procedimiento de optimización {‘lbfgs’, ‘sgd’, ‘adam’}, default=’adam’. El procedimiento ‘adam’ funciona bastante bien en conjuntos de datos relativamente grandes (con miles de muestras de entrenamiento o más). Sin embargo, para conjuntos de datos pequeños, ‘lbfgs’ puede converger más rápido y funcionar mejor.
batch_size Tamaño de minilotes. Si ‘lbfgs’, el clasificador no usará minibatch.
learning_rate_init Ratio de aprendizaje, defecto=0.001
Algunos parametros de salida a consultar:
best_loss_ : mínimo coste encontrado.
coefs_ y intercepts_ : matrices de pesos y bias.
n_features_in_, n_layers_ y n_outputs_ : nodos de entrada, número de capas y nodos de salida
Algunos métodos de más uso:
fit(X, y) : Ajusta el modelo con las matrices X e y.
get_params([deep]) : Devuelve los parámetros del estimador
partial_fit(X, y[, classes]) : actualiza el modelo con una iteración sencilla con los datos aportados
predict(X) : devuelve las etiquetas predichas y a partir de una matriz de características X.
predict_log_proba(X) : da el logaritmo de probabilidades estimadas.
predict_proba(X) : da la estimación de etiquetas en probabilidades.
score(X, y[, sample_weight]) : devuelve la exactitud (accuracy) de un conjunto de datos y etiquetas de prueba.
set_params(**params) : Establece los parámetros del estimador
Observaciones¶
El método clásico de descenso de gradiente necesita atravesar todos los datos de entrenamiento cada vez que se actualizan los parámetros del modelo. Cuando N es muy grande, requiere enormes recursos de cálculo y tiempo de cálculo, lo que básicamente no es factible en el proceso real.
Para resolver este problema, el descenso de gradiente estocástico (SGD) utiliza la pérdida de una sola muestra de entrenamiento para aproximar la pérdida promedio.
El método lbfgs usa un método quasi-Newton. Mientras el método de gradiente descenso, que sólo usa las derivadas primeras, los métodos de Newton son de segundo orden y usan las derivadas parciales segundas, pero tiene el inconveniente de ser muy costosos en proceso. Una alternativa son las aproximaciones quasi-Newton como por ejemplo la fórmula de Broyden-Fletcher-Goldfarb-Shanno (BFGS).
Inicialmente, las redes neuronales solo tenían tres tipos de capas: ocultas, de entrada y de salida. Estas tres capas se conocen como capas densas porque cada neurona está completamente conectada a la siguiente capa. Y las neuronas son solo soportes, no hay conexiones directas.
Las redes neuronales modernas tienen muchos tipos de capas adicionales. Además de las capas densas clásicas, ahora también tenemos capas de abandono, convolucionales, de agrupación y recurrentes. Las capas densas a menudo se entremezclan con estos otros tipos de capas.
Algunas observaciones al diseño del número de capas y neuronas del perceptron¶
Poniendo el foco en las capas densas hay que determinar dos parámetros: el número de capas ocultas y el número de neuronas por capa.
Los problemas que requieren más de dos capas ocultas son raros fuera del aprendizaje profundo. Dos o menos capas suelen ser suficientes en conjuntos de datos simples. Sin embargo, con conjuntos de datos complejos que involucran series de tiempo o visión por computadora, puede requerir capas adicionales.
El requisito de nº de capas ocultas puede ser:
Ninguna: en problemas linealmente separables.
1: aproxima cualquier función que contenga un mapeo continuo de un espacio finito a otro.
2: puede representar un límite de decisión arbitrario con precisión arbitraria con funciones de activación racionales y puede aproximar cualquier mapeo suave con cualquier precisión.
>2: las capas adicionales pueden aprender representaciones complejas (una especie de ingeniería de características automática).
El número de neuronas en las capas ocultas
El uso de muy pocas neuronas en las capas ocultas dará como resultado el underfitting. El ajuste insuficiente ocurre cuando hay muy pocas neuronas en las capas ocultas para detectar adecuadamente las señales en un conjunto de datos complicado.
El uso de demasiadas neuronas en las capas ocultas puede dar lugar a varios problemas. En primer lugar, demasiadas neuronas en las capas ocultas pueden provocar un sobreajuste (overfitting). El sobreajuste ocurre cuando la red neuronal tiene tanta capacidad de procesamiento de información que la cantidad limitada de información contenida en el conjunto de entrenamiento no es suficiente para entrenar todas las neuronas en las capas ocultas. Un segundo problema puede ocurrir incluso cuando los datos de entrenamiento son suficientes. Una cantidad excesivamente grande de neuronas en las capas ocultas puede aumentar el tiempo de procesamiento hasta poder hacerlo inviable.
Se suelen usar algunas reglas empíricas como empezar por una capa oculta con un número prefijado de neuronas y luego ir subiendo una a una este número hasta que se alcanza un máximo en el score. Después se puede probar a añadir una nueva capa oculta, prefijando su número de neuronas e ir subiendo este para ver como se comporta el score.
Las capas ocultas junto a la de salida suelen tener una estructura piramidal, de forma que la capa siguiente suele tener menor número de neuronas.
Cuando la capa de entrada tiene pocas neuronas se puede comenzar usando este número en la primera capa oculta e ir uno a uno subiendo su número.
Heaton por ejemplo indica las siguientes reglas empíricas para determinar las neuronas de las capas ocultas:
El número de neuronas ocultas debe estar entre el tamaño de la capa de entrada y el tamaño de la capa de salida.
El número de neuronas ocultas debe ser 2/3 del tamaño de la capa de entrada, más el tamaño de la capa de salida.
El número de neuronas ocultas debe ser inferior al doble del tamaño de la capa de entrada.
Heaton, J. (2008). Introduction to neural networks with Java. Heaton Research, Inc.
Heaton, J., McElwee, S., Fraley, J., & Cannady, J. (2017, May). Early stabilizing feature importance for TensorFlow deep neural networks. In 2017 International Joint Conference on Neural Networks (IJCNN) (pp. 4618-4624). IEEE.
Puerta XOR¶
cols = ['x1', 'x2', 'XOR']
puerta_xor=[[0,0,0], [1,0,1], [0,1,1], [1,1,0]]
df = pd.DataFrame(puerta_xor, columns=cols)
df.head()
| x1 | x2 | XOR | |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 1 |
| 2 | 0 | 1 | 1 |
| 3 | 1 | 1 | 0 |
X = []
y = []
for ix in np.linspace(0, 1, 20):
for iy in np.linspace(0, 1, 20):
if (ix <= 0.5 and iy <= 0.5) or (ix>0.5 and iy >0.5):
y.append(0)
else:
y.append(1)
X.append([ix, iy])
y=np.asarray(y)
X=np.asarray(X)
color=['blue', 'red']
for lbl in np.unique(y):
plt.scatter(X[y==lbl][:,0], X[y==lbl][:,1], c=color[lbl])

## Importación de la clase del perceptrón multicapa
from sklearn.neural_network import MLPClassifier
## Inicialización y creación del objeto clasificador
mlp = MLPClassifier(max_iter=200,activation = 'tanh',solver='lbfgs',random_state=1, hidden_layer_sizes=(4,2))
mlp.fit(X, y)
print("Exactitud del conjunto de entrenamiento: {:.3f}".format(mlp.score(X, y)))
Exactitud del conjunto de entrenamiento: 1.000
mlp.n_features_in_, mlp.hidden_layer_sizes, mlp.n_outputs_, "Total de capas=", mlp.n_layers_
(2, (4, 2), 1, 'Total de capas=', 4)
color=['blue', 'red']
y_pred = mlp.predict(X)
for lbl in np.unique(y_pred):
plt.scatter(X[y_pred==lbl][:,0], X[y_pred==lbl][:,1], c=color[lbl])

from sklearn.metrics import accuracy_score
nn = NeuralNetwork(eta=0.01, epocas=40000, hiddenLayers=[50], seed=1, activacion='logistic')
nn.fit(X, y),
y_pred= nn.predict(X)
print("Exactitud - Accuracy=", accuracy_score(y_true=y, y_pred=y_pred))
color=['blue', 'red']
for lbl in np.unique(y_pred):
plt.scatter(X[y_pred==lbl][:,0], X[y_pred==lbl][:,1], c=color[lbl])
Epoca =====> 1 Coste ====> 0.2500977942609019
Epoca =====> 5001 Coste ====> 0.13607151164272266
Epoca =====> 10001 Coste ====> 0.023335407427707126
Epoca =====> 15001 Coste ====> 0.012173614925513674
Epoca =====> 20001 Coste ====> 0.008606188242294689
Epoca =====> 25001 Coste ====> 0.006911612597868417
Epoca =====> 30001 Coste ====> 0.00584588331982002
Epoca =====> 35001 Coste ====> 0.005059220105951967
Epoca =====> 40000 Coste ====> 0.004434195276895715
Exactitud - Accuracy= 0.74

Clasificar con la red neuronal el conjunto Iris¶
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target']=iris['target']
df.head()
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | target | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | 0 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 0 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | 0 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | 0 |
Se toma el conjunto completo como conjunto de entrenamiento.¶
Se toman las 4 características
from sklearn.model_selection import train_test_split
X = df.values[:,0:4]
y = df.values[:,4]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1, stratify=y)
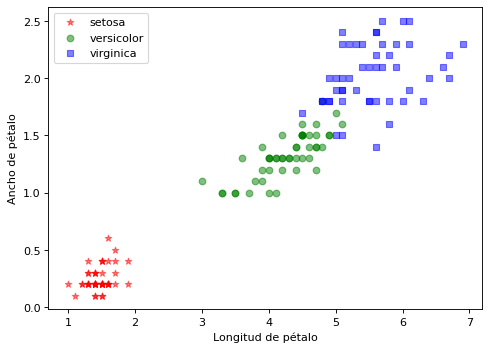
import matplotlib.pyplot as plt
clases = iris['target_names']
marcas = ['*', 'o', 's']
color = ['red', 'green', 'blue']
plt.figure(figsize=(7, 5), dpi=80)
for i in range(len(clases)):
plt.scatter(X[y==i,2], X[y==i,3], c=color[i], alpha=0.5, marker=marcas[i], label=clases[i])
plt.xlabel("Longitud de pétalo")
plt.ylabel("Ancho de pétalo")
plt.legend(loc='upper left')
plt.show()
Clasificación con MLPClassifier¶
## Importación de la clase del perceptrón multicapa
from sklearn.neural_network import MLPClassifier
## Inicialización y creación del objeto clasificador
mlp = MLPClassifier(max_iter=5000,activation = 'logistic',solver='lbfgs',random_state=1, hidden_layer_sizes=(5,4))
mlp.fit(X_train, y_train)
print("Exactitud del conjunto de entrenamiento: {:.3f}".format(mlp.score(X_train, y_train)))
print("Exactitud del conjunto de prueba: {:.3f}".format(mlp.score(X_test, y_test)))
Exactitud del conjunto de entrenamiento: 1.000
Exactitud del conjunto de prueba: 1.000
mlp.n_features_in_, mlp.n_layers_, mlp.n_outputs_
(4, 4, 3)
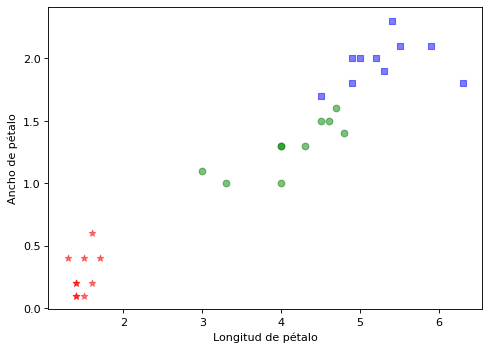
Visualización de la calidad de la clasificación
Los colores indican la estimación y las marcas gráficas el valor real
#Xplot=X_train
Xplot=X_test
#yplot=y_train
yplot=y_test
yplot_pred = mlp.predict(Xplot)
import matplotlib.pyplot as plt
marcas = ['*', 'o', 's']
clases=iris['target_names']
color = ['red', 'green', 'blue']
plt.figure(figsize=(7, 5), dpi=80)
for i in range(len(Xplot)):
estimado = yplot_pred[i]
ik = int(estimado)
ic = int(yplot[i])
plt.scatter(Xplot[i,2], Xplot[i,3], c=color[ik], alpha=0.5, marker=marcas[ic])
plt.xlabel("Longitud de pétalo")
plt.ylabel("Ancho de pétalo")
plt.show()
Estructura tridimensional de proteinas (AlphaFold)¶
Senior, A. W., Evans, R., Jumper, J., Kirkpatrick, J., Sifre, L., Green, T., … & Hassabis, D. (2019). Protein structure prediction using multiple deep neural networks in the 13th Critical Assessment of Protein Structure Prediction (CASP13). Proteins: Structure, Function, and Bioinformatics, 87(12), 1141-1148.
El procedimiento seguido ha resultado paradigmático en este tipo de metodologías:
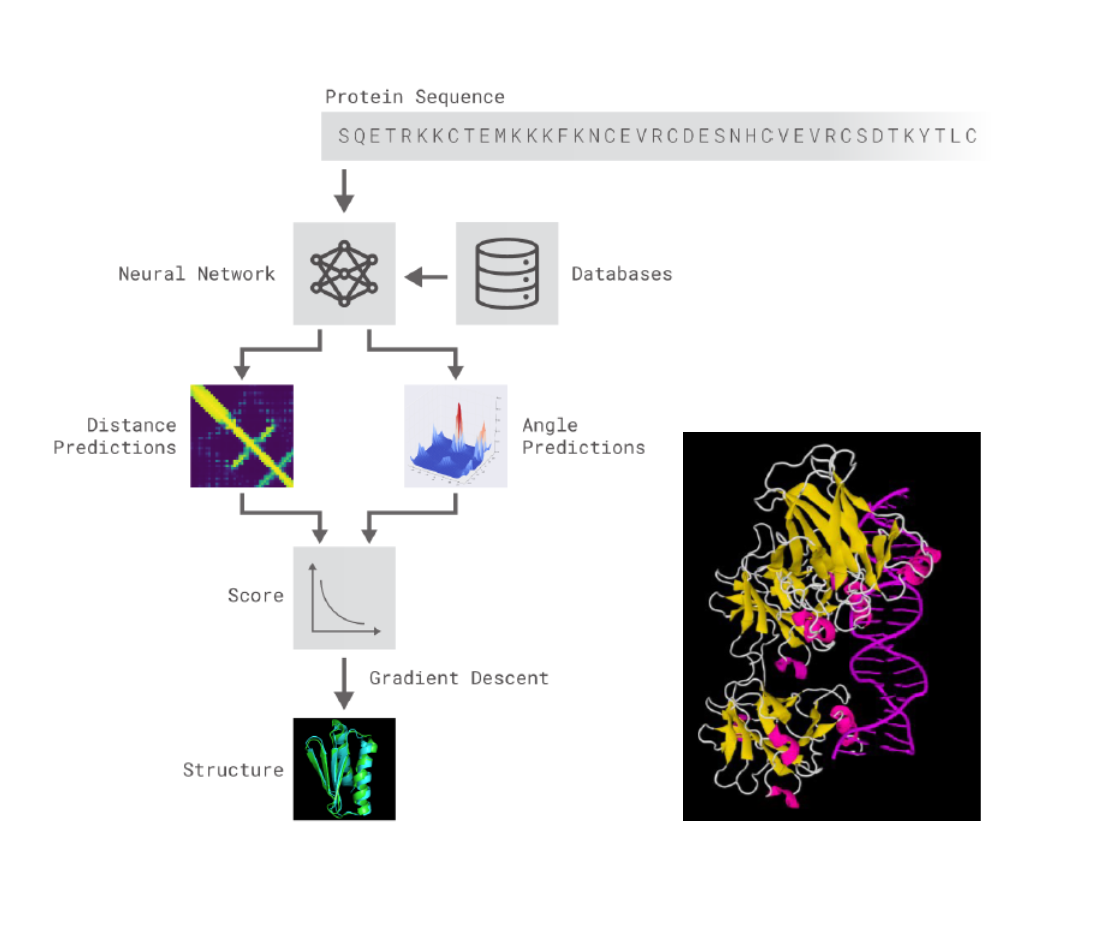
Es posible acceder a un cuaderno Jupyter en Google Colaboratory donde predecir en la red AlphaFold creandose una copia del cuaderno en el Drive de cada usuario desde el enlace:
https://colab.sandbox.google.com/github/deepmind/alphafold/blob/main/notebooks/AlphaFold.ipynb
Referencias¶
Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Learning representations by back-propagating errors. nature, 323(6088), 533-536.
Rodrigo Fernandes de Mello, Moacir Antonelli Ponti . Machine Learning. A Practical Approach on the Statistical Learning Theory Springer (2018).
Brett Lantz. Machine Learning with R. Expert Techniques for Predictive Modeling to Solve All Your Data Analysis Problems. Packt Publishing (2015)
D. Floreano y C. Mattiussi . Bio Inspired Artificial Intelligence: Theories, Methods, and Technologies, MIT press (2008).
S. Mitra . Introduction to Machine Learning and Bioinformatics. CRC Press (2008).
Dr . Joshua F. Wiley. R Deep Learning Essentials , Packt Publishing (2016).
Scott V. Burger. Introduction to Machine Learning with R. Rigorous mathematical analysis. O’Reilly (2018).
Artículos para profundizar¶
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3507700/#B15
http://science.sciencemag.org/content/313/5786/504
https://www.tandfonline.com/doi/full/10.1080/13102818.2017.1364977
A.K.Jain & J. Mao. Artificial Neural Networks: A IEEE, March (1996)
Anders Krogh. What are artificial neural networks? Nat. Biotech., 26 , 2 2008
Senior et al. Protein structure prediction using multiple Deep neural networks in the 13th CASP13. Proteins , 87:1141 1148 (2019)
Wang, L., J. Chen and M. Marathe . TDEFSI: Theory Guided Deep Learning Based Epidemic Forecasting with Synthetic Information . arXiv:2002.04663v1 [ stat.OT ] 28 Jan 2020