
4.5 Análisis de HMM¶
Tenemos tres fases:
Aprendizaje: dada una lista de secuencias de sı́mbolos, ¿podemos aprender los parámetros \((\pi^{(0)} , P, E )\) de un HMM? Algoritmo de Baum-Welch.
Evaluación: una vez que el modelo está ajustado, ¿cuál es la verosimilitud de una secuencia dada? Algoritmo “forward”.
Descodificación: una vez que el modelo está ajustado, ¿cuál es el la secuencia de estados más probable para generar de una secuencia de sı́mbolos dada? Algoritmo de Viterbi.
4.5.1 Aprendizaje¶
Dos casos:
Si conocemos las secuencias de estados asociadas a cada secuencia de sı́mbolos
Si no los conocemos
Caso 1: conocemos las secuencias de estados asociadas a los símbolos¶
En proteı́nas, esto equivale a conocer la estructura secundaria de cada secuencia de aminoácidos.
La verosimilitud de que una secuencia de estados \(\mathcal{est}=\{x_1,\ldots,x_n\}\) genere una secuencia de símbolos \(\mathcal{sim}=\{s_1,\ldots,s_n\}\) es:
Entonces el método de máxima verosimilitud permite estimar los parámetros como frecuencias relativas en el conjunto de entrenamiento.
Note
En el conjunto de entrenamiento
Probabilidades de transición:
Probabilidades de emisión:
Vector inicial:
Caso 2: no conocemos las secuencias de estados asociadas a los símbolos¶
En proteı́nas, esto equivale a conocer solamente las secuencias de aminoácidos.
Este es el caso más frecuente en la práctica.
En este caso se puede aplicar el algoritmo de Baum-Welch, que estima también las probabilidades de transición aunque no conozcamos las secuencias de estados.
4.5.2 Evaluación¶
Warning
¡Tras la fase de aprendizaje!
Dada una secuencia de sı́mbolos (aminoácidos), ¿puedo calcular la probabilidad de observarla de acuerdo con el HMM?
Equivale a calcular la probabilidad marginal
donde tenemos que sumar sobre todos los posibles caminos que generan la secuencia.
El número de posibilidades crece exponencialmente con \(n\).
Se usa programación dinámica para calcular la suma anterior de manera eficiente. El resultado es el algoritmo “forward”.
4.5.3 Descodificación¶
Warning
¡Tras la fase de aprendizaje!
Dada una secuencia de sı́mbolos (aminoácidos), ¿puedo calcular la secuencia de estados ocultos (estructuras secundarias) que maximiza la verosimilitud \(\mathbb{P}\{\mathcal{est}, \mathcal{sim} \}\)?
Es un proceso de máxima verosimilitud.
Se usa programación dinámica eligiendo la rama de mayor probabilidad en cada paso de la secuencia.
El resultado es el algoritmo de Viterbi.
Algoritmo de Viterbi¶
Para el ejemplo anterior:
Tenemos una cadena con tres símbolos observados: \(G-W-M\) (en ese orden). Queremos conocer la cadena de estados subyacente más probable.
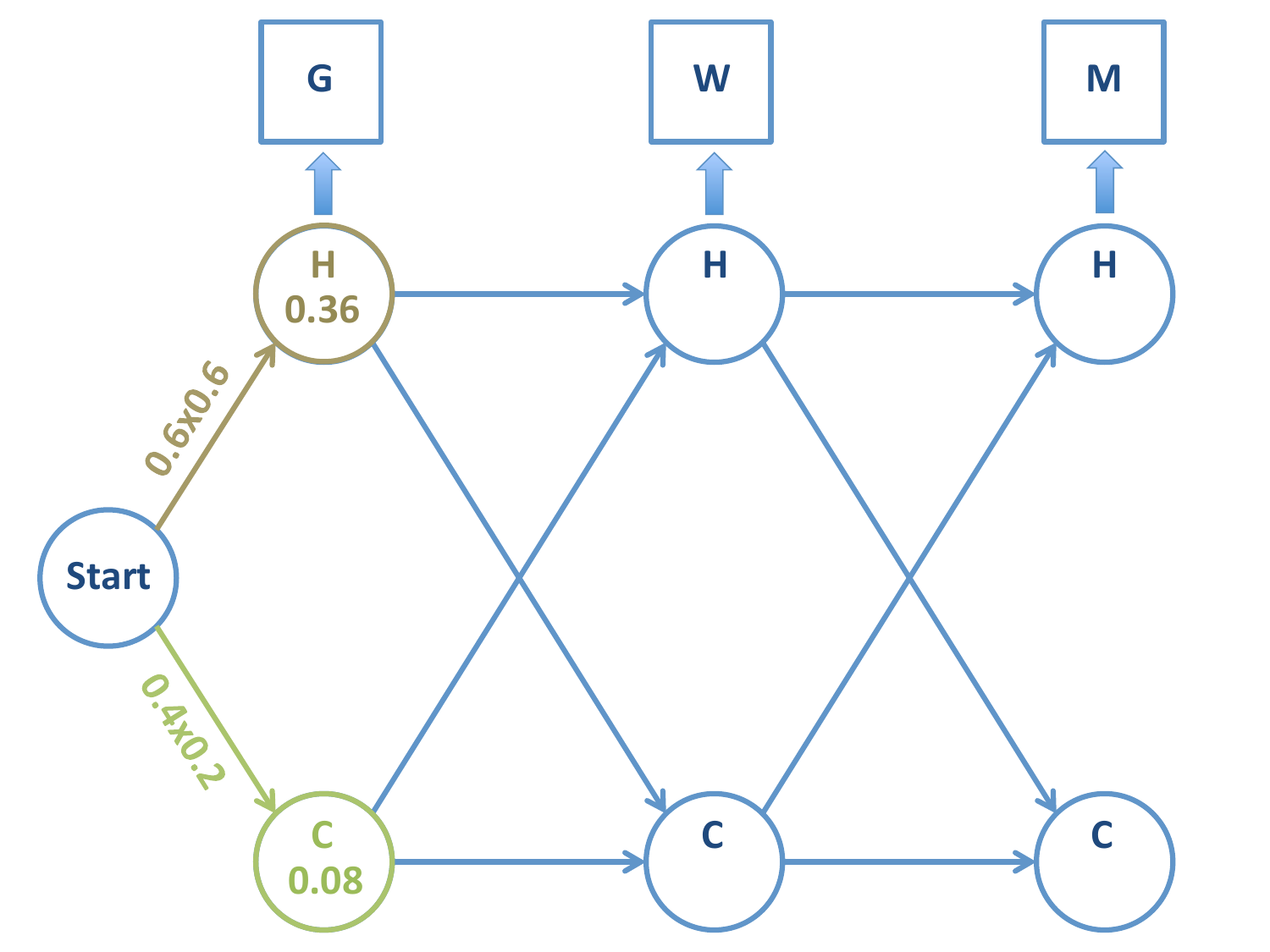
Fig. 13 Viterbi¶
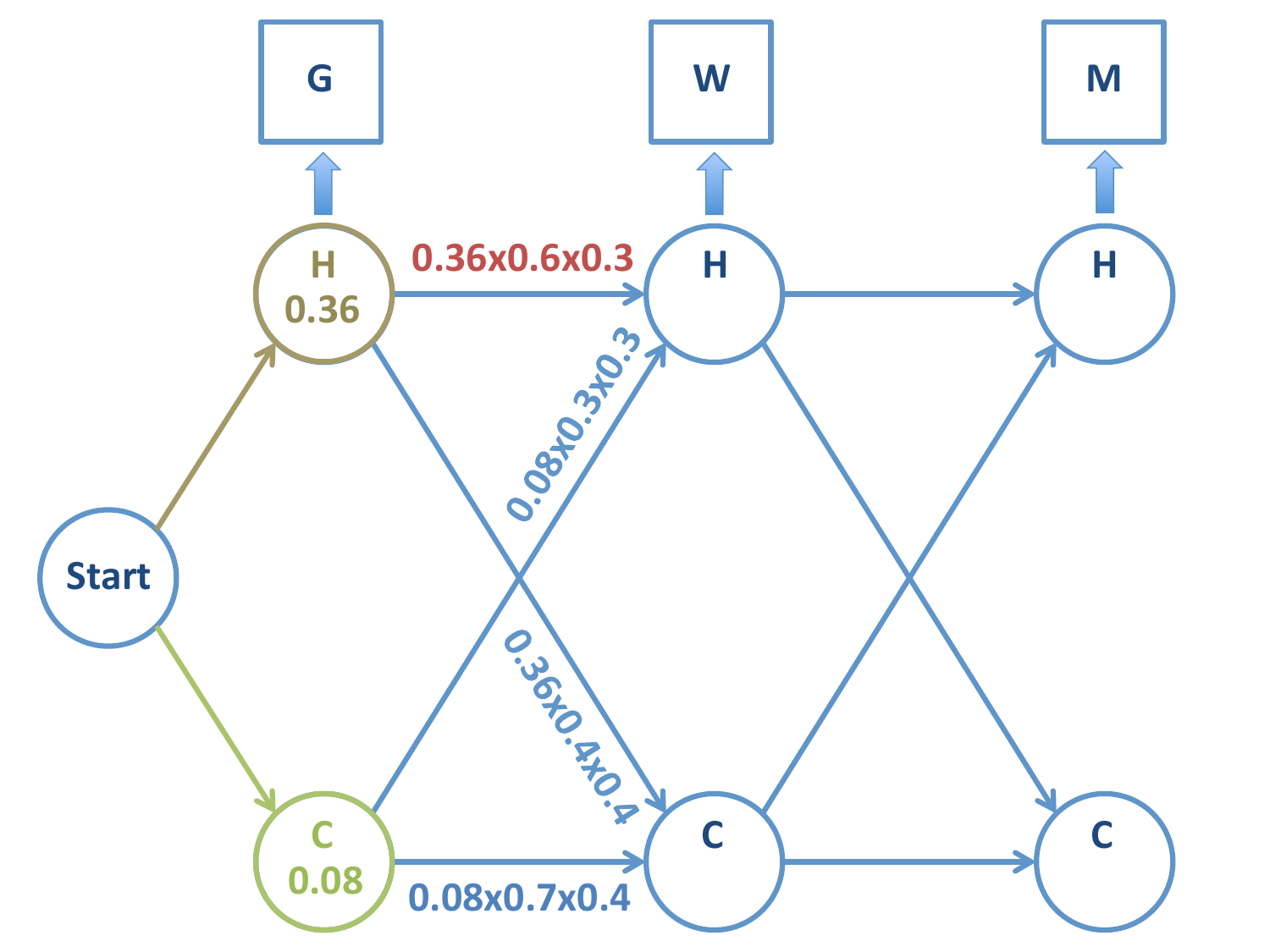
Fig. 14 Viterbi¶
Siguiente paso: calculamos las probabilidades de las 4 cadenas posibles.
Importante
Partimos de
Probabilidad de la cadena \(H-H\):
Probabilidad de la cadena \(C-H\):
Importante
En este momento podemos rechazar la cadena \(C-H\) frente a \(H-H\), ya que la primera tiene menos probabilidad de ocurrir. Aquí radica la potencia del algoritmo de Viterbi: dejamos de calcular las probabilidades de todas las cadenas sucesivas a \(C-H\).
Note
Esta selección se hace a nivel de nodo: rechazamos uno de los caminos que llegan a un nodo.
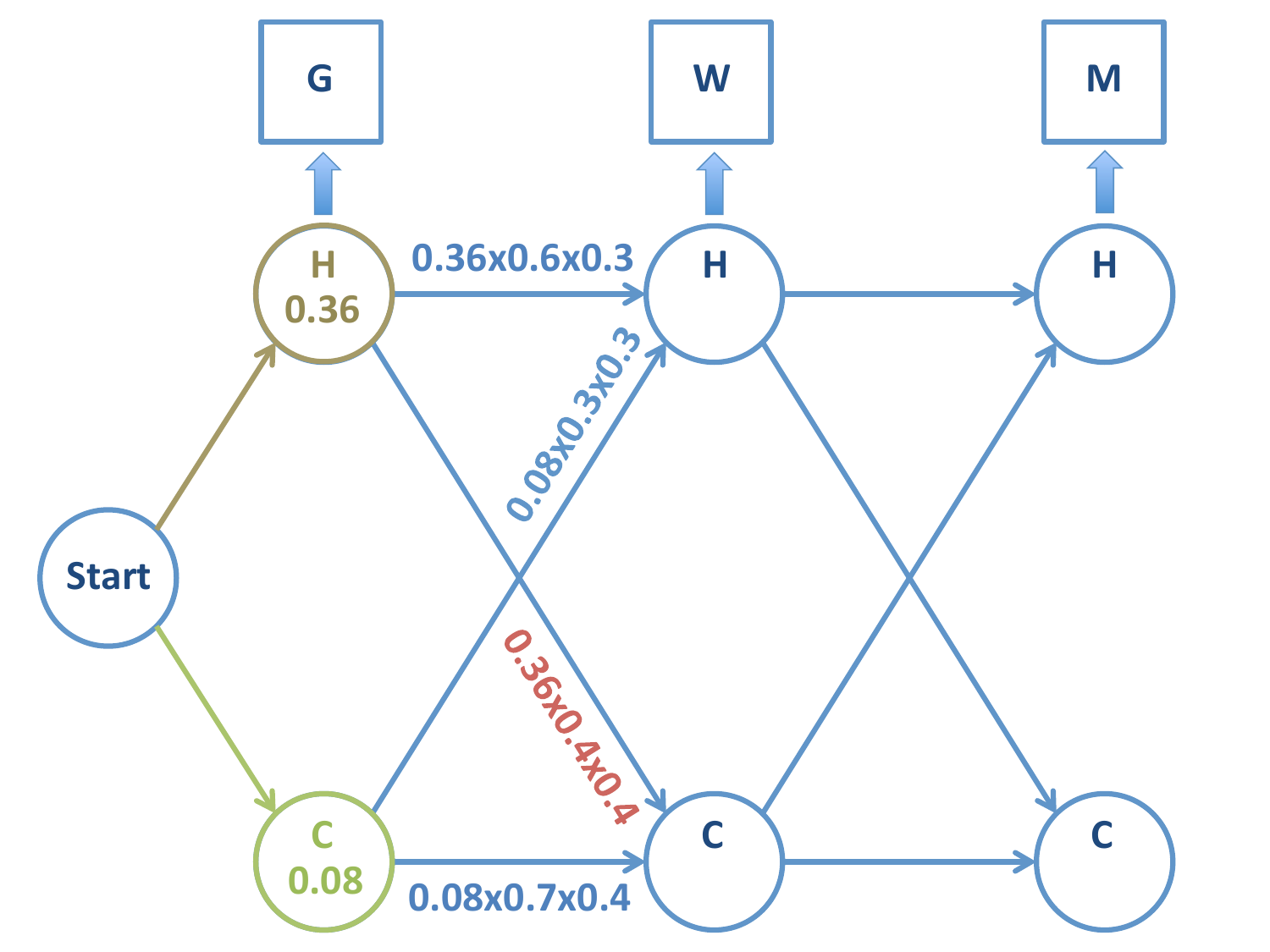
Fig. 15 Viterbi¶
Probabilidad de la cadena \(H-C\):
Probabilidad de la cadena \(C-C\):
Igualmente, aquí podemos descartar la cadena \(C-C\) frente a \(H-C\) (y todas las sucesivas cadenas de \(C-C\)).
Hemos rechazado los caminos \(C-C\) y \(C-H\), por tanto podemos rechazar que la cadena pasa por nodo \(C\) en la primera etapa.
En cada caso: tomamos el camino de mayor probabilidad y marcamos el nodo.
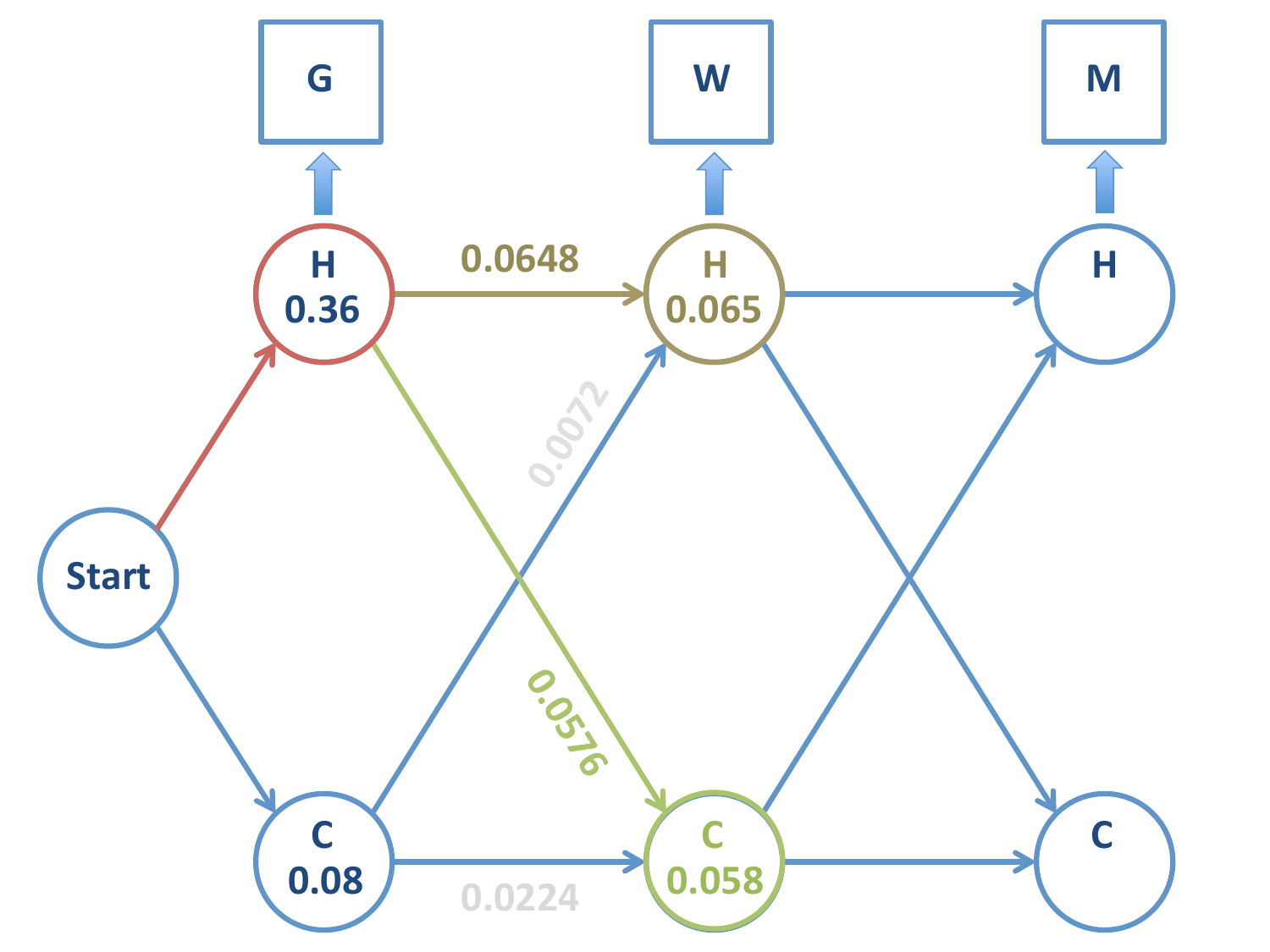
Fig. 16 Viterbi¶
Importante
NO podemos rechazar, no obstante, el nodo \(C\) en la segunda etapa de la cadena (emisión \(=W\)). En este momento disponemos de la probabilidad que la cadena sea \(H-C\) ó \(H-H\), pero la cadena de Markov continua.
Continuamos el proceso hasta la última etapa de la cadena: calculamos las probabilidades de las cadenas restantes, que son:
\(H-H-H\)
\(H-H-C\)
\(H-C-H\)
\(H-C-C\)
Note
En la tercera etapa el estado observado es \(M\)
Partimos de esta situación
Probabilidad de la cadena \(H-H-H\)
Probabilidad de la cadena \(H-H-C\)
Probabilidad de la cadena \(H-C-H\)
Probabilidad de la cadena \(H-C-C\)
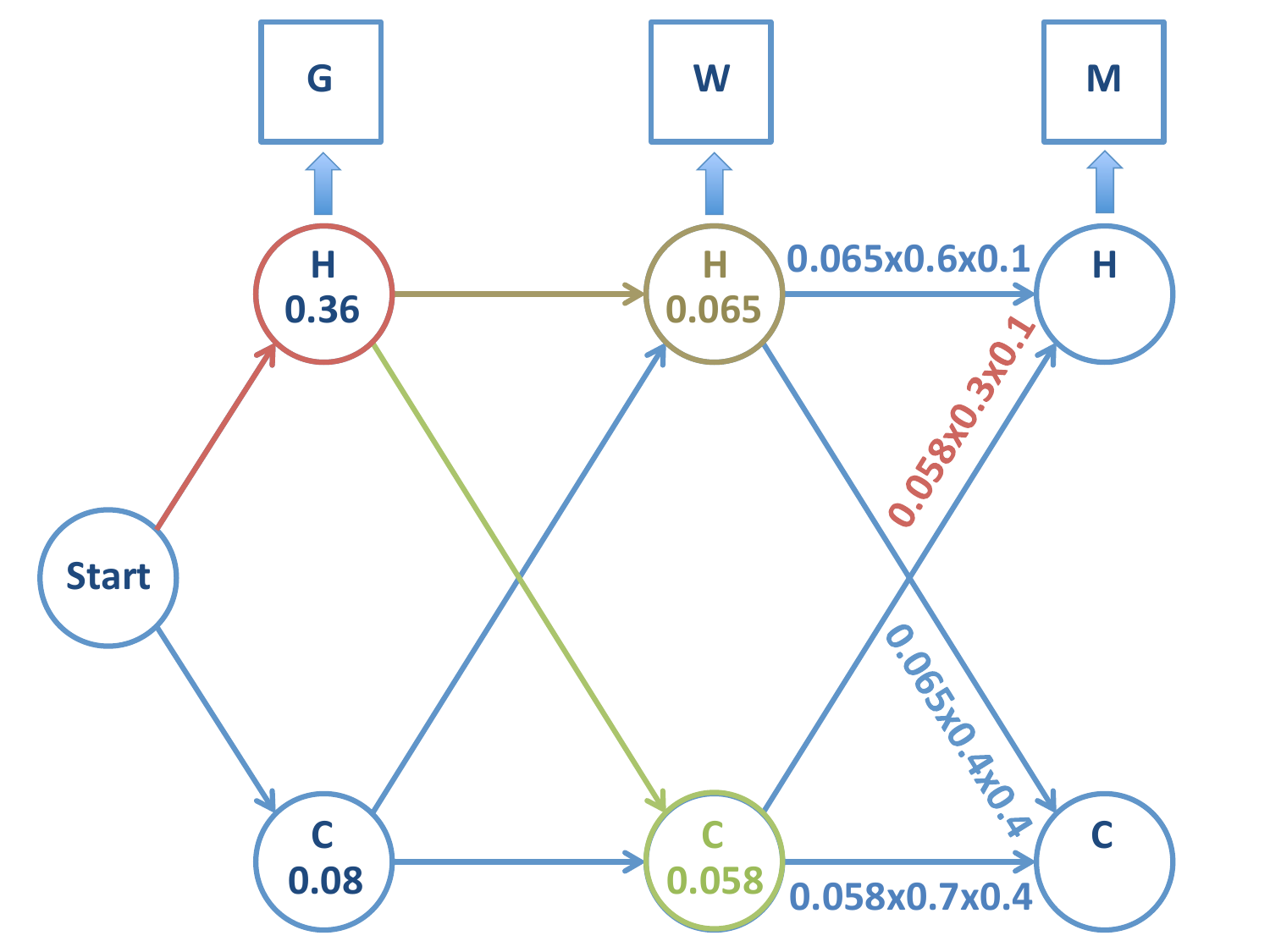
Fig. 17 Viterbi¶
Observaciones
De los dos caminos que llegan a \(H\) en la tercera etapa, el más probable es el que viene de \(C\), por tanto descartamos el camino \(H-H-H\).
De los dos caminos que llegan a \(C\) en la tercera etapa, el más probable es el que proviene de \(C\) en la segunda. Descartamos el camino \(H-H-C\).
Las dos observaciones anteriores hacen que descartemos el estado \(H\) en la segunda etapa. Esto no es trivial, pues si hubiésemos detenido el proceso en dicha etapa, el último estado más probable hubiera sido \(H\)!
Los dos posibles caminos son
\(H-C-H\) con una probabilidad de 0.001728
\(H-C-C\) con una probabilidad de 0.0161
El último estado es el de mayor verosimilitud: \(H-C-C\).
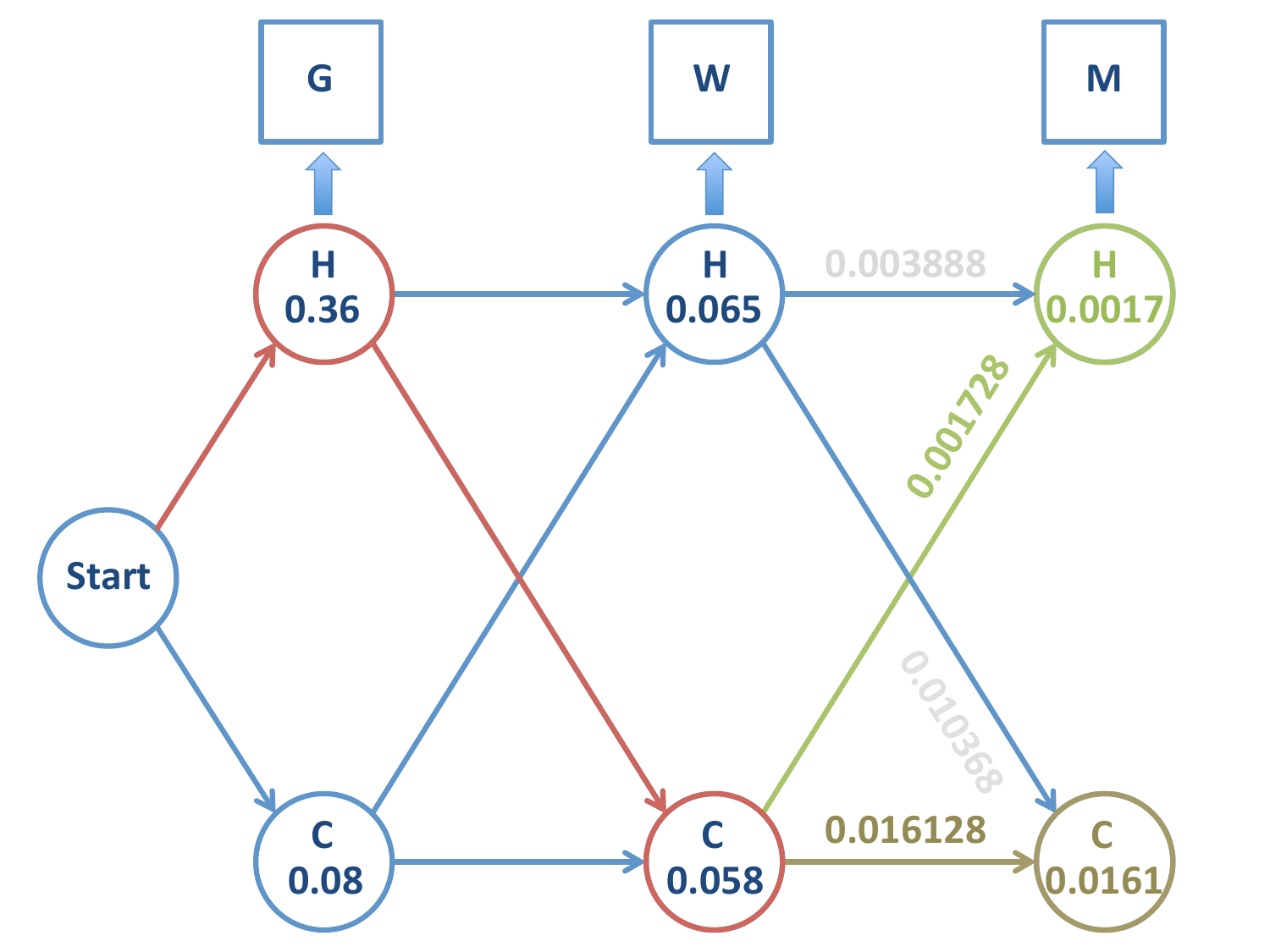
Fig. 18 Viterbi¶