
import numpy as np
import matplotlib.pyplot as plt
Práctica 1: Pasos elementales del GA¶
Los Algoritmos Genéticos (GA de sus siglas en inglés) son herramientas computacionales de búsqueda de soluciones óptimas mediante la aplicación de las leyes de la evolución y selección en genomas que codifican el problema que se pretende resolver.
Así como los sistemas naturales han encontrado soluciones óptimas durante su evolución, estos métodos incluyen mecanismos de variación para explorar nuevas soluciones junto con la capacidad de selección de las mejores en cada paso.
De esta manera, los GA son muy eficaces para encontrar soluciones óptimas de problemas complejos en los que existe un gran número de extremos locales.
En esta sección vamos a definir algunos de los pasos elementales de los algoritmos genéticos, a saber:
Codificación del problema en los genotipos / fenotipos
Creacción de una población de genotipos
Replicación con mutación
Selección de los mejores fenotipos / genotipos
Dejamos para la última sección la finalización del GA con los pasos:
Repetición de esta secuencia hasta convergencia
Comprobación e interpretación del resultado en el problema original
Codificación del problema: genotipos¶
Este primer paso es esencial en la aplicación de los GA para la resolución de un problema. Las posibles soluciones deben ser relacionadas con las posibles configuraciones de los genotipos. Por ejemplo, podemos relacionar una propiedad del sistema con una posición en la secuencia del genotipo.
En el estudio de una ruta metabólica de \(\nu\) (nu) reacciones, un 1 en la posición \(i\)-ésima significa que esa reacción tienen lugar (existe la enzima), mientras que un 0 representa lo contrario, que la reacción no se da.
Con esta codificación, un genoma está representando una posible ruta metabólica y todas las posibles rutas metábolicas quedan asignadas en todos los posibles genomas binarios de longitud nu, en total \(2^\nu\).
Una población inicial de tamaño \(N\) constituye, por tanto, un punto de partida para explorar las posibles rutas metabólicas que relacionan un sustrato con un producto.
Esta población se puede generar de acuerdo a un patrón o completamente al azar si no se tiene ninguna información previa. Por ejemplo, se podría definir la proporción de 1 en los genotipos que forman la población inicial con el parámetro probuno.
probuno = 0.1
N = 100
nu = 10
binGen = np.zeros((N,nu))
(np.random.uniform(size=10)<probuno).astype('int')
array([0, 0, 0, 0, 0, 0, 1, 0, 0, 0])
for genoma in range(N):
binGen[genoma,:]= (np.random.uniform(size=10)<probuno).astype('int')
binGen[:10,:]
array([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],
[0., 1., 1., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 1., 1.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 0., 0., 1., 0., 0., 0., 0., 0., 0.]])
binGen.sum()
101.0
En una función
def crearGenoma(N,nu,probUno):
binGen = np.zeros((N,nu))
for genoma in range(N):
binGen[genoma,:]= (np.random.uniform(size=10)<probuno).astype('int')
return binGen
Asignación del fitness: fenotipos¶
Una vez que se ha definido el significado de un genotipo, una población de genomas de longitud nu representa una conjunto de rutas metabólicas factibles que realizarán una transformación de una manera más o menos eficaz.
Precisamente, la eficacia de la ruta define el fitness de ese genoma y constituye su fenotipo. Podríamos pensar que una ruta es más eficaz energéticamente si es más larga y, por lo tanto, su fitness depende del número de reacciones que la constituyen. Además, podríamos suponer que las reacciones del final de la ruta aportan más al fitness.
En este caso, el fitness se podría calcular de manera inmedita a partir del número de 1 del genotipo y la posición que ocupan.
vector = np.arange(nu)+1
vector
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
binGen[0,:]
array([1., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
vector.dot(binGen[0,:])
1.0
fitnessV = []
for ii in range(N):
fit = vector.dot(binGen[ii,:])
fitnessV.append(fit)
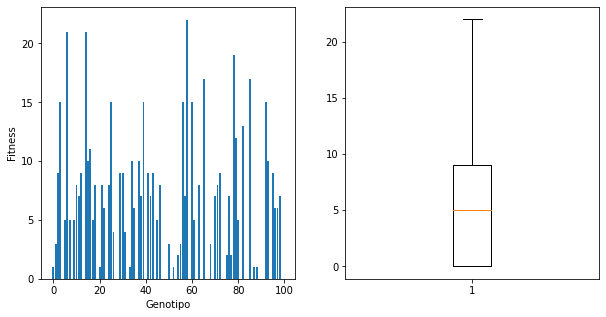
f,ax=plt.subplots(nrows=1,ncols=2,figsize=(10,5))
ax[0].bar(np.arange(len(fitnessV)),fitnessV)
ax[0].set_xlabel('Genotipo')
ax[0].set_ylabel('Fitness')
ax[1].boxplot(fitnessV)
plt.show()
# ordenamos de mayor a menor
indexOrder = np.argsort(fitnessV)
indexOrder
array([49, 32, 36, 40, 44, 47, 48, 51, 53, 59, 62, 64, 28, 66, 69, 73, 74,
81, 83, 84, 86, 89, 90, 91, 94, 67, 27, 99, 19, 13, 8, 4, 23, 0,
52, 87, 88, 20, 33, 54, 77, 75, 55, 50, 68, 1, 31, 26, 45, 17, 9,
7, 61, 5, 80, 97, 96, 22, 35, 76, 57, 98, 42, 70, 11, 38, 10, 71,
63, 21, 18, 24, 46, 29, 2, 72, 30, 41, 95, 12, 43, 34, 37, 93, 15,
16, 79, 82, 92, 56, 39, 60, 3, 25, 65, 85, 78, 14, 6, 58])
fitnessV_order = np.asarray(fitnessV)[indexOrder]
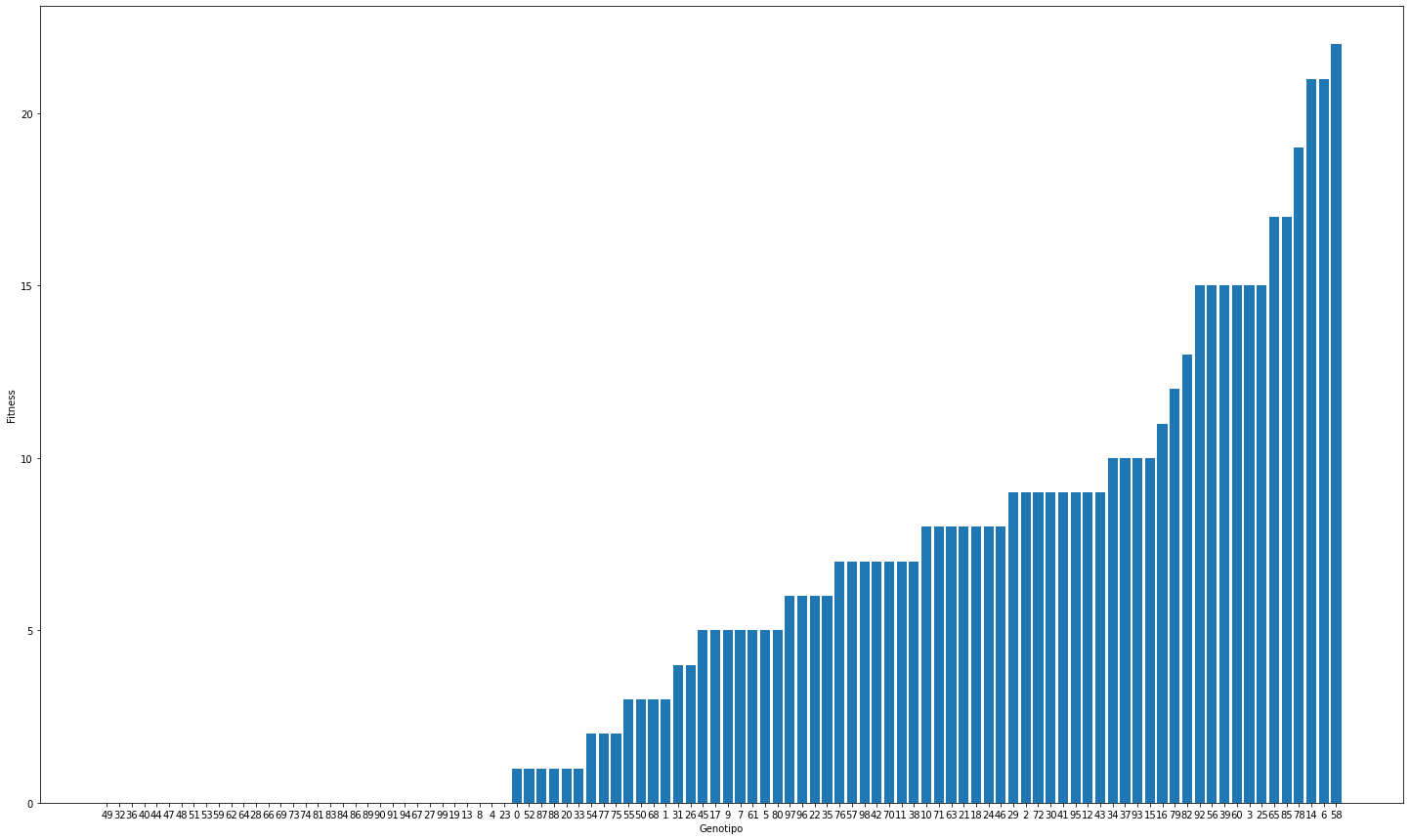
f,ax=plt.subplots(nrows=1,ncols=1,figsize=(25,15))
ax.bar(np.arange(len(fitnessV_order)),fitnessV_order)
ax.set_xlabel('Genotipo')
ax.set_xticks(np.arange(len(indexOrder)),indexOrder)
ax.set_ylabel('Fitness')
Text(0, 0.5, 'Fitness')
binGen[:10,:]
array([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],
[0., 1., 1., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 1., 1.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 0., 0., 1., 0., 0., 0., 0., 0., 0.]])
binGen.sum(axis=1)
array([1., 1., 1., 3., 0., 1., 3., 1., 0., 2., 1., 2., 1., 0., 3., 2., 3.,
1., 1., 0., 1., 2., 1., 0., 1., 3., 2., 0., 0., 1., 1., 1., 0., 1.,
1., 1., 0., 2., 1., 3., 0., 1., 1., 2., 0., 1., 1., 0., 0., 0., 1.,
0., 1., 0., 1., 1., 2., 1., 4., 0., 2., 1., 0., 1., 0., 3., 0., 0.,
1., 0., 1., 1., 1., 0., 0., 1., 1., 1., 3., 2., 1., 0., 3., 0., 0.,
3., 0., 1., 1., 0., 0., 0., 2., 1., 0., 1., 1., 1., 1., 0.])
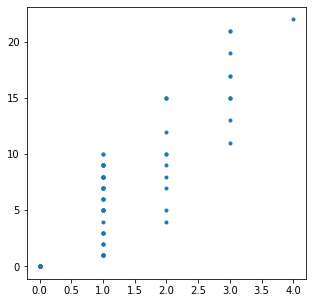
Relación entre el número de genes y el fitness
f,ax=plt.subplots(nrows=1,ncols=1,figsize=(5,5))
ax.plot(binGen.sum(axis=1),fitnessV,'.')
[<matplotlib.lines.Line2D at 0x7fea812ac400>]
Mutación de un gen¶
Una de las maneras de incluir diversidad en la población a partir de los genotipos existentes consiste en considerar una probabilidad de mutación por dígito que durante el proceso de replicación produce genotipos distintos.
probMutacion = 0.1
numsample = int(np.round(np.random.uniform(low=1,high = probMutacion*nu,size=1)))
numsample
1
genToMutate = np.random.choice(np.arange(nu),size=numsample,replace=False)
genToMutate
array([9])
binGen[:10,:]
array([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],
[0., 1., 1., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 1., 1.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[1., 0., 0., 1., 0., 0., 0., 0., 0., 0.]])
for gg in genToMutate:
binGen[:,gg]=(binGen[:,gg]+1)%2
binGen[:10,:]
array([[1., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 1.],
[0., 1., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 1.],
[0., 1., 0., 0., 0., 0., 0., 0., 1., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 1.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[1., 0., 0., 1., 0., 0., 0., 0., 0., 1.]])
Función mutación¶
Define una función mutN que realice la mutación por dígito y aplícala a toda la población de tamaño \(N\). Antes guarda la población en otra matriz, por ejemplo, binGen_anterior
binGen[1,:]
array([0., 0., 1., 0., 0., 0., 0., 0., 0., 1.])
def mutN(genotipo,probMut,numGenesGenotipo):
numGenesMutar = int(np.round(np.random.uniform(low=1,high = probMut*numGenesGenotipo,size=1)))
for el in np.arange(genotipo.shape[0]):
genesToMutate = np.random.choice(np.arange(numGenesGenotipo),size=numGenesMutar,replace=False)
for gen in genesToMutate:
genotipo[el,gen]=(genotipo[el,gen]+1)%2
return genotipo,numGenesMutar
probUno = 0.1
N = 100
nu = 10
binGen = crearGenoma(N,nu,probUno)
binGenInit = binGen.copy()
binGen[:10,:]
array([[0., 0., 1., 0., 0., 1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 1., 0., 1., 1., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 1.],
[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 1., 0., 1., 0.],
[0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 0., 1., 0.]])
probMutacion = 0.1
binGen,nGen = mutN(binGen,probMutacion,nu)
print('Número de genes mutados: ',nGen)
binGen[:10,:]
Número de genes mutados: 1
array([[0., 1., 1., 0., 0., 1., 0., 0., 0., 0.],
[0., 1., 1., 0., 0., 1., 0., 1., 1., 0.],
[1., 0., 0., 0., 1., 0., 0., 0., 0., 1.],
[1., 0., 0., 0., 0., 1., 0., 0., 0., 0.],
[0., 0., 1., 1., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 1., 0., 0., 0., 1.],
[1., 0., 0., 0., 0., 0., 1., 0., 1., 0.],
[1., 0., 0., 0., 0., 0., 1., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 0.]])
Combinación de los nuevos genomas y los anteriores y ranking¶
Después de realizar la replicación con mutación de todos los genotipos de la población hay que proceder a agrupar y ordenar la población para preparar la selección de los genotipos con el mayor fitness.
combinedGenoma = np.zeros((2*N,nu))
combinedGenoma[:N,:] = binGenInit
combinedGenoma[N:,:] = binGen
combinedGenoma[:10,:]
array([[0., 0., 1., 0., 0., 1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 1., 0., 1., 1., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 1.],
[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 1., 0., 1., 0.],
[0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 0., 1., 0.]])
combinedGenoma[N:N+10,:]
array([[0., 1., 1., 0., 0., 1., 0., 0., 0., 0.],
[0., 1., 1., 0., 0., 1., 0., 1., 1., 0.],
[1., 0., 0., 0., 1., 0., 0., 0., 0., 1.],
[1., 0., 0., 0., 0., 1., 0., 0., 0., 0.],
[0., 0., 1., 1., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 1., 0., 0., 0., 1.],
[1., 0., 0., 0., 0., 0., 1., 0., 1., 0.],
[1., 0., 0., 0., 0., 0., 1., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 0.]])
fitnessV = []
vector = np.arange(nu)+1
for ind in range(combinedGenoma.shape[0]):
fit = vector.dot(combinedGenoma[ind,:])
fitnessV.append(fit)
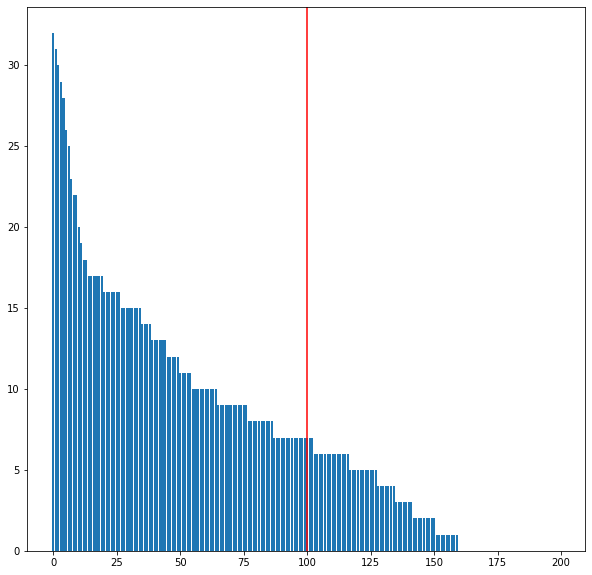
f,ax=plt.subplots(nrows=1,ncols=1,figsize=(10,10))
ax.bar(np.arange(len(fitnessV)),fitnessV)
ax.axvline(N,color='red')
<matplotlib.lines.Line2D at 0x7fea819fa2e0>

fitnessOrderIndex = np.argsort(fitnessV)[::-1]
orderedGenoma = np.zeros((2*N,nu))
for ii,fit in enumerate(fitnessOrderIndex):
orderedGenoma[ii,:] = combinedGenoma[fit,:]
fitnessVOrd = []
vector = np.arange(nu)+1
for ind in range(orderedGenoma.shape[0]):
fit = vector.dot(orderedGenoma[ind,:])
fitnessVOrd.append(fit)
f,ax=plt.subplots(nrows=1,ncols=1,figsize=(10,10))
ax.bar(np.arange(len(fitnessVOrd)),fitnessVOrd)
ax.axvline(N,color='red')
<matplotlib.lines.Line2D at 0x7fea81a2f490>
Selección¶
Una de las maneras de seleccionar los genotipos que se han creado por replicación-mutación es la denominada elistista, que consiste en crear una población del mismo tamaño \(N\) a partir de los genotipos con mejor fitness. En otras palabras, elegir los \(N\) primeros del ranking. Utiliza una selección elistista para escoger una población de \(N\) genotipos para la siguiente generación.
nuevaPoblacion = orderedGenoma[:N,:]
Representación de los resultados¶
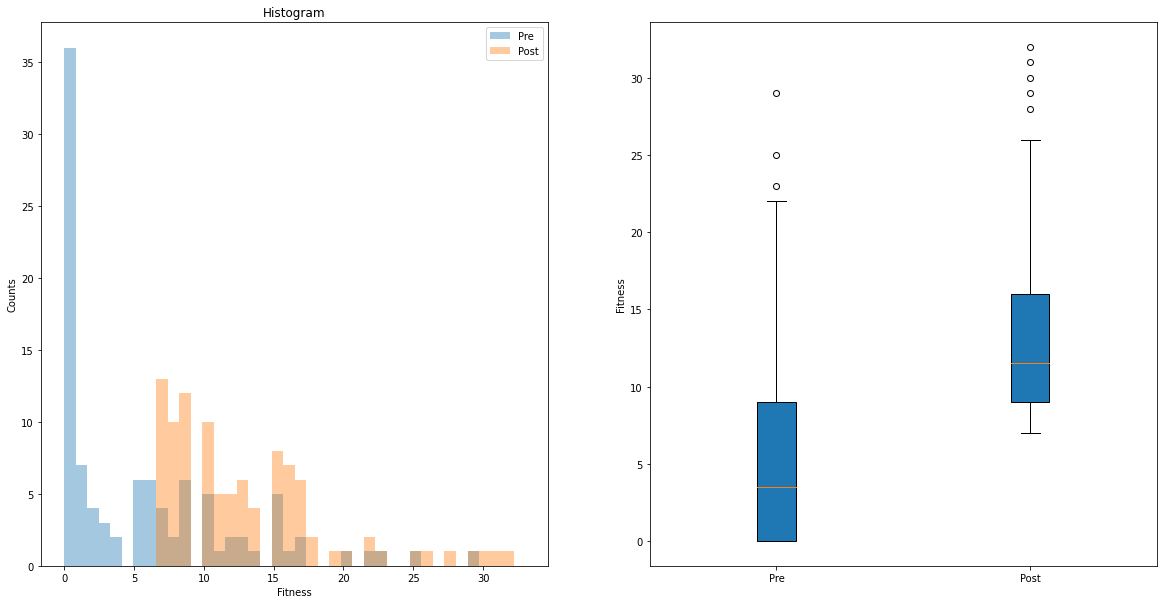
Calculamos y representamos los nuevos valores del fitness de la población y comparamos con los de la población anterior. En concreto, el fitness medio y su varianza, así como el mínimo y el máximo. También representa su histograma. Compara con los valores que tenía la población en el paso inicial.
nuevaPoblacion.shape
(100, 10)
binGenInit.shape
(100, 10)
fitnessANT = []
fitnessPOST = []
vector = np.arange(nu)+1
for gen in range(N):
fitA = vector.dot(binGenInit[gen,:])
fitP = vector.dot(nuevaPoblacion[gen,:])
fitnessANT.append(fitA)
fitnessPOST.append(fitP)
fitnessANT = np.asarray(fitnessANT)
fitnessPOST = np.asarray(fitnessPOST)
bothFitness = [fitnessANT,fitnessPOST]
maxFit = np.max((np.max(fitnessANT),np.max(fitnessPOST)))
f,ax=plt.subplots(nrows=1,ncols=2,figsize=(20,10))
ax[0].hist(fitnessANT,bins=40,range=(0,maxFit+1),alpha=0.4,label='Pre')
ax[0].hist(fitnessPOST,bins=40,range=(0,maxFit+1),alpha=0.4,label='Post')
ax[1].boxplot(bothFitness,vert=True,patch_artist=True,labels=['Pre','Post'])
ax[0].set_xlabel('Fitness')
ax[1].set_ylabel('Fitness')
ax[0].set_ylabel('Counts')
ax[0].set_title('Histogram')
ax[0].legend()
plt.show()
Ejercicio: Bucle de evolución-selección¶
Utiliza los ejercicios anteriores para definir un bucle de replicación-selección de la población a partir de una población inicial. El número de iteraciones debe ser suficientemente elevado para permitir la convergencia de la fitness medio de la población.
¿Podrías formular alguna conjetura sobre hacia qué fitness medio tenderá la población?
¿Cómo depende la convergencia con la tasa de mutación?