
05.2 Redes Neuronales - Modelo Bicapa¶
import pandas as pd
from IPython import display
import numpy as np
run 05.0_Redes_Neuronales_Utilidades.ipynb
<Figure size 432x288 with 0 Axes>
Fundamento matemático del perceptrón simple bicapa¶
[Rosenblatt, 1958] introdujo el perceptrón simple formado por dos capas, una de entrada con n neuronas y una de salida con m neuronas. [Widrow and Hoff, 1960] introdujeron el modelo ADAptative LInear Neuron (Adaline) tambien bicapa. Los modelos bicapa tienen la siguiente forma
La función de activación más habitual es
Por último, la variable objetivo \(y^r\), donde \(r=1...N\) se convierte en un vector de \(m\) posiciones. Así la etiqueta késima tiene todo ceros menos un 1 en la posición k. Por tanto se tiene:
El entrenamiento se basa en minimizar la función de errores al cuadrado por el procedimiento iterativo de gradiente de descenso. Donde la función de errores al cuadrado es:
Siendo \({\large y_i^r}\) los valores reales en cada neurona de salida y \({\large a_i^r}\) la activación del ejemplo \({\large r}\) del conjunto de entrenamiento. Es necesario considerar el coste de los \({\large N}\) ejemplos de entrenamiento en la función \({\large C}\) que depende de los \({\large w_{ij}}\) y los \({\large b_{i}}\) en las etapas de entrenamiento, cuando se está fijando sus valores. Mientras que los \({\large x_i}\) son valores que no varían en esta etapa y que los proporciona el conjunto de entrenamiento. El aprendizaje consistirá en ir minimizando el error cuadrático, que es la función \({\large C(w_{ij}, b_i)}\). Se Sabe que el vector gradiente
Va en la dirección del mayor incremento de \(C\) en el punto del dominio \((b_i, w_{i})\). Recordar que el subindice \(i\) hace referencia sólo a la posición de la neurona de salida . Pero como lo que nos interesa es ir en sentido del mayor decremento del error cuadrático se toma el valor negativo \(-\nabla C((b_i, w_{i}))\). Incrementar el vector \((b_i, w_{i})\) con todo el vector gradiente \(-\nabla C(b_i, w_{i})\) puede ocasionar un salto en el mínimo local y no conseguir la convergencia deseada. Por eso se procede con pequeños incrementos utilizando el factor de aprendizaje \(\eta\) (que se pronuncia “eta”), con lo que queda:
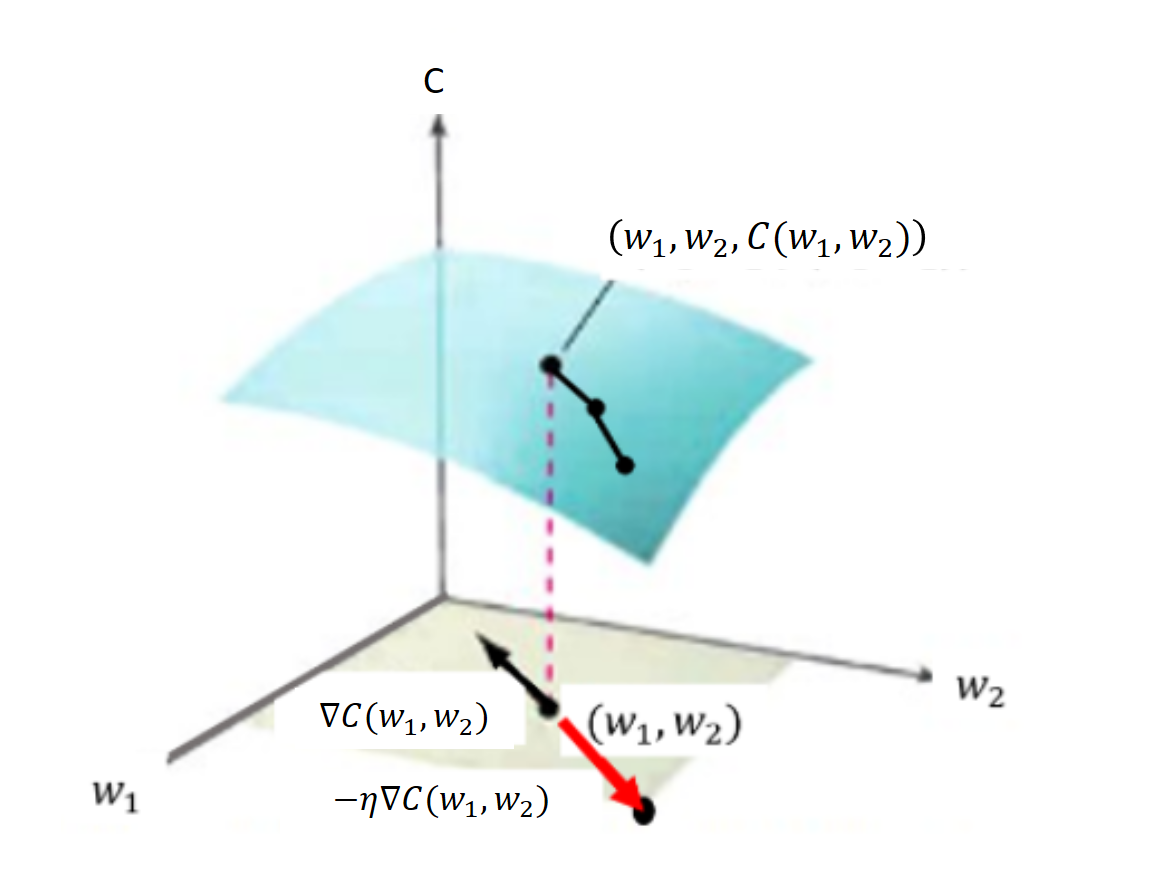
El gradiente en un peso y un bias concreto es igual
Si hay que realizar una clasificación binaria (verdadero-falso o 0-1) a partir de un conjunto de datos de entrada bastaría con usar una neurona de salida con tantos nodos de entrada como dimensiones tenga el conjunto de características \(X\).
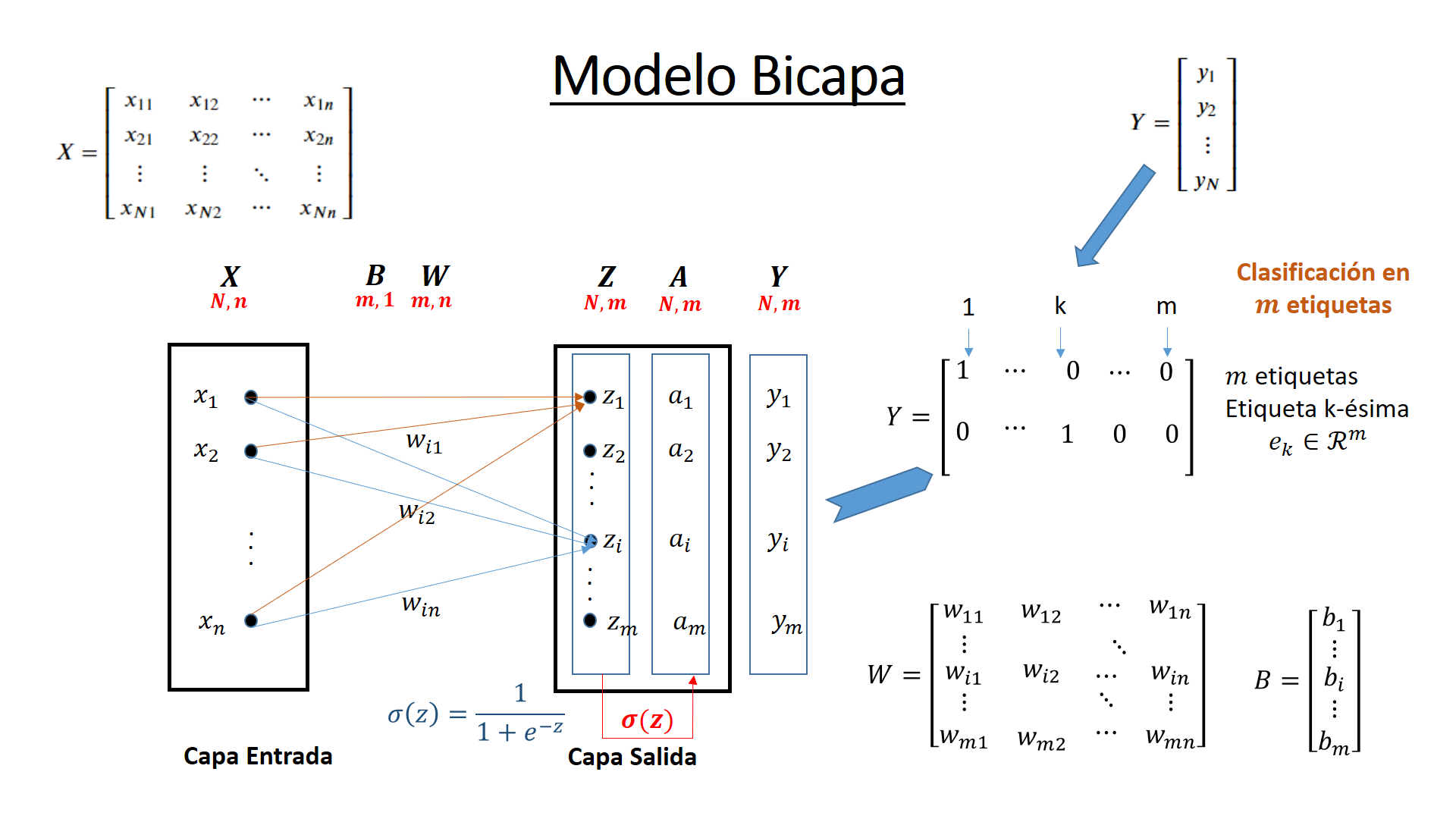
Si el número de clases del conjunto \(Y\) es \(m\), conjunto discreto de etiquetas que toma valores en \({e_1, e_2, ..., e_m}\) se adopta un modelo de \(m\) neuronas de salida. Si la dimensión de \(X\) es \(n\) se tendrían \(n\) nodos o neuronas en la capa de entrada y \(m\) nodos o neuronas en la capa de salida.
Cada neurona en la capa de salida está conectada a las \(n\) neuronas de la capa de entrada. Además las neuronas de la capa de salida no se conectan entre sí. Los parámetros que conectan la capa de entrada con la capa de salida se pueden poner en una matriz de \(m\) filas y \(n\) columnas
El conjunto objetivo \(Y\) en lugar de manejarlo como un vector de dimensión 1, se maneja como un vector de dimensión \(m\). Así si el valor es \(e_1\), se tomará el valor \((1,0,...,0)\) y la etiqueta \(e_m\) el valor \((0,0,..,1)\). Si el conjunto de entrenamiento tiene \(N\) elementos se pasará a entrenar dos matrices de datos. Una matriz \(X\) de \(N\) filas y \(n\) columnas con las características y una matriz con \(N\) filas y \(m\) columnas con valores 0 y 1 con los objetivos.
Resolución del algoritmo matricialmente
El entrenamiento se realiza con operaciones matriciales por dos motivos:
Se obtiene un codigo Python más sintético y fácil de elaborar y seguir.
Las operaciones las realiza en bloque la librería con un mejor rendimiento.
Resolución matricial, proceso en bloque¶
Proceso hacia adelante o Forward: dada una matriz \({\large X}\) de N registros que entran a la neurona y dados unos pesos y bias definidos en las matrices \({\large W}\) y \({\large B}\), se tendrá la siguiente salida de forma matricial:
Donde \(\oplus\) es una operación sobrecargada que suma \(b_i\) a cada columna de la matriz resultante del producto \(X \cdot W^T\)
El error neto entre los valores reales \({\large Y}\) y los activados en el paso anterior de la neurona vendrán dados por
Matriz \({\large \Delta}\): La tasa de variación del error cuadrático por unidad de entrada, que es la parte común de los dos gradientes anteriores, se puede poner matricialmente mediante la matriz \({\large \Delta}\)
En la obtención de la matriz \({\large \Delta}\) se utiliza el producto de Hadamard (\(s \odot t\)), que aplicado a dos matrices o vectores (\(s=s_{ij}\) y \(t=t_{ij}\)), es el producto de sus elementos término a término (\([s_{ij} \cdot t_{ij}]\))
Entrenamiento: Es posible entrenar el perceptrón en T etapas, partiendo de valores aleatorios en las matrices \(W\) y \(B\) en \(t=1\), de forma que estas matrices en sucesivos \({\large t}\) adoptarán:
Siendo \({\large 1}\) una matriz columna de \(N\) unos que realiza el sumatorio de las filas de \(\Delta ^T\)
Implementación con código propio del modelo Bicapa¶
Modelo bicapa de \(p\) neuronas de entrada y \(m\) neuronas de salida
def sigmoid(x):
return 1.0/(1.0 + np.exp(-x))
def sigmoid_derivada(x):
return sigmoid(x)*(1.0-sigmoid(x))
def tanh(x):
return np.tanh(x)
def tanh_derivada(x):
return 1.0 - x**2
class AdalineGD(object):
"""ADAptive LInear NEuron classifier.
Parametros
------------
eta : float Ratio de aprendizaje (entre 0.0 y 1.0)
n_iter : int Pasos sobre el conjunto de datos de entrenamiento.
capas: capas[0] las neuronas de entrada, capas[1] las neuronas de salida
random_state : int Generador de semillas de números aleatorios para inicializar los pesos.
Atributos
-----------
w_ : Array de dimensión 1 con los pesos después del ajuste.
cost_ : lista de Suma-de-cuadrados de los valores de la función coste en cada Paso del algoritmo.
"""
def __init__(self, eta=0.01, n_iter=50, capas=[2, 3], random_state=1):
self.eta = eta
self.n_iter = n_iter
self.random_state = random_state
self.nNeurInput=capas[0]
self.nNeurOutput=capas[1]
def fit(self, X, y):
""" Ajuste con los datos de entrenamiento.
Parametros
----------
X : {Tipo array}, shape = [n_ejemplo, n_caracteristicas]
Vectores de entrenamiento, donde n_ejemplo es el numero de ejemplos y
n_caracteristicas es el número de características.
y : tipo array, shape = [n_ejemplo] Valores Objetivo.
Retorno
-------
self : objecto
"""
# Con esto agregamos la unidad de Bias a la capa de entrada
ones = np.atleast_2d(np.ones(X.shape[0]))
X = np.concatenate((ones.T, X), axis=1)
rgen = np.random.RandomState(self.random_state)
self.w_ = []
for k in range(self.nNeurOutput):
self.w_.append(rgen.normal(loc=0.0, scale=0.01,size=1 + self.nNeurInput))
self.cost_ = []
k=0
for i in range(self.n_iter):
net_input = self.net_input(X) ## Z
output = self.activation(net_input) ## A
errors = (y - output) ### A - Y
deltas = errors * self.activation_prima(net_input) ## (A - Y) * sigma_prima(Z)
self.w_ += self.eta * np.transpose(X.T.dot(deltas)) ## W += eta* Delta _T * X
cost = (errors**2).sum() / 2.0
k += 1
if k==200:
print("Epoca =====>", i+1, "Coste ====>", cost)
k=0
self.cost_.append(cost)
print("Epoca =====>", self.n_iter, "Coste ====>", cost)
return self
def net_input(self, X):
"""Calculate net input"""
return np.dot(X, np.transpose(self.w_)) ## X * W^T
def activation(self, X):
"""Compute linear activation"""
return sigmoid(X)
def activation_prima(self, X):
"""Compute linear activation"""
return sigmoid_derivada(X)
def predict(self, X):
"""Return class label after unit step"""
# Con esto agregamos la unidad de Bias a la capa de entrada
ones = np.atleast_2d(np.ones(X.shape[0]))
X = np.concatenate((ones.T, X), axis=1)
neuronasOut = self.activation(self.net_input(X))
#print("neuronasOut", neuronasOut)
return neuronasOut
Clasificar con AdalineGD el conjunto Iris¶
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target']=iris['target']
df.head()
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | target | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | 0 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 0 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | 0 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | 0 |
Preparación de matrices X e y. Visualización¶
from sklearn.model_selection import train_test_split
X, y = df.values[:,2:4], df.values[:,4]
#X_train, X_test, y_train, y_test =train_test_split(X, y, test_size=0.25, random_state=0, stratify=y)
import matplotlib.pyplot as plt
clases = iris['target_names']
marcas = ['*', 'o', 's']
color = ['red', 'green', 'blue']
plt.figure(figsize=(7, 5), dpi=80)
for i in range(len(clases)):
plt.scatter(X[y==i,0], X[y==i,1], c=color[i], alpha=0.5, marker=marcas[i], label=clases[i])
plt.xlabel("Longitud de pétalo")
plt.ylabel("Ancho de pétalo")
plt.legend(loc='upper left')
plt.show()
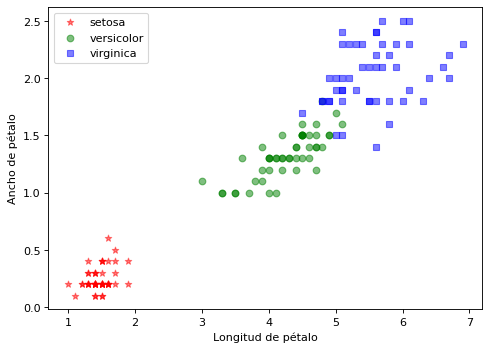
Preparamos las estructuras de datos de salida para entrenar¶
Adecuamos las etiquetas de \(\{0, 1, 2\}\) al modelo binario \(\{(1,0,0); (0,1,0); (0,0,1)\}\)
## Primero se determina el número de neuronas de salida en función de las distintas etiquetas
nNeur = len(np.unique(y))
## Se convierte la lista inicial y en una lista multineurona
yNeur = [[0 for k in range(nNeur)] for i in range(np.size(y))]
for i in range(np.size(y)):
yNeur[i][int(y[i])] = 1
nEntrada = np.size(X[0])
print("Nº neuronas=", nEntrada, nNeur)
misCapas=[nEntrada, nNeur]
print(misCapas)
clf = AdalineGD(eta=0.01, n_iter=2500, capas=misCapas, random_state=1)
clf.fit(X, yNeur)
Nº neuronas= 2 3
[2, 3]
Epoca =====> 200 Coste ====> 22.476731371479918
Epoca =====> 400 Coste ====> 20.463078887525846
Epoca =====> 600 Coste ====> 19.569397767672147
Epoca =====> 800 Coste ====> 19.044232108145877
Epoca =====> 1000 Coste ====> 18.691518103933248
Epoca =====> 1200 Coste ====> 18.434887944811592
Epoca =====> 1400 Coste ====> 18.237931501266992
Epoca =====> 1600 Coste ====> 18.080908693488148
Epoca =====> 1800 Coste ====> 17.952107234200376
Epoca =====> 2000 Coste ====> 17.84409624273631
Epoca =====> 2200 Coste ====> 17.75191055232349
Epoca =====> 2400 Coste ====> 17.672092904978285
Epoca =====> 2500 Coste ====> 17.636016099547206
<__main__.AdalineGD at 0x7f6cf7dd03a0>
print(clf.w_)
y_pred= clf.predict(X)
print("Hecho. Número de predicciones", y_pred.shape[0])
[[ 6.56335393 -1.80522402 -2.75501148]
[ -2.81821411 1.68509239 -3.41750344]
[-10.87746601 0.71555428 4.49594094]]
Hecho. Número de predicciones 150
tot_Test = y_pred.shape[0]
tot_aciertos = 0
for i in range(tot_Test):
estimado = y_pred[i]
etiqueta, = np.where(np.isclose(estimado, np.max(estimado)))
real = y[i]
if int(real) == int(etiqueta[0]):
tot_aciertos += 1
#print('Instancia %s Clase real %s Clase estimada %s - Probabilidad estimada %s \n' %(X[i], real, etiqueta[0], estimado))
print('Precisión del clasificador %s \n' %(tot_aciertos*100/tot_Test))
Precisión del clasificador 94.66666666666667
Finalmente se visualiza la estimación realizada¶
Se visualiza de forma independiente los separadores de clase basados en la matriz de pesos
# Dado w_i0 + w_i1*x + w_i2*y = 0
# y = (-1/w_i2) * (w_i0 + w_i1*x)
def getOrdenadaRecta(matW, iNeur, x):
return (-1/matW[iNeur,2])*(matW[iNeur,0] + matW[iNeur,1]*x)
import matplotlib.pyplot as plt
marcas = ['*', 'o', 's']
clases=iris['target_names']
color = ['red', 'green', 'blue']
plt.figure(figsize=(7, 5), dpi=80)
lst_x = np.linspace(min(X[:,0]), max(X[:,0]), 50)
for i in range(len(X)):
estimado = y_pred[i]
etiqueta, = np.where(np.isclose(estimado, np.max(estimado)))
ik = int(etiqueta[0])
ic = int(y[i])
plt.scatter(X[i,0], X[i,1], c=color[ik], alpha=0.5, marker=marcas[ic])
## Se grafican las 3 rectas delimitadoras
plt.plot(lst_x, getOrdenadaRecta(clf.w_, 0, lst_x))
plt.plot(lst_x, getOrdenadaRecta(clf.w_, 1, lst_x))
plt.plot(lst_x, getOrdenadaRecta(clf.w_, 2, lst_x))
plt.xlabel("Longitud de pétalo")
plt.ylabel("Ancho de pétalo")
plt.show()
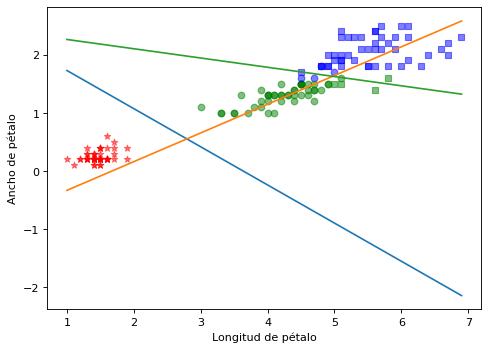
Se observa que las 3 clases que son linealmente separables. Cada una de las clases cumple estar por encima de una de las recta maximizando el valor de la activación.
Finalmente se hace una ejecución con todas las características disponibles en Iris¶
La dimensión de las variables de entrada será 4 en lugar de 2
X = df.values[:,0:4]
X[0]
array([5.1, 3.5, 1.4, 0.2])
nEntrada = np.size(X[0])
misCapas=[nEntrada, nNeur]
print(misCapas)
clf = AdalineGD(eta=0.01, n_iter=2500, capas=misCapas, random_state=1)
clf.fit(X, yNeur)
[4, 3]
Epoca =====> 200 Coste ====> 19.28194366928518
Epoca =====> 400 Coste ====> 19.25711071110704
Epoca =====> 600 Coste ====> 14.896082223094423
Epoca =====> 800 Coste ====> 18.497782472218105
Epoca =====> 1000 Coste ====> 16.964519390517584
Epoca =====> 1200 Coste ====> 16.462906265462927
Epoca =====> 1400 Coste ====> 16.157110388488228
Epoca =====> 1600 Coste ====> 15.950085548406152
Epoca =====> 1800 Coste ====> 15.79613913500432
Epoca =====> 2000 Coste ====> 15.672644477328108
Epoca =====> 2200 Coste ====> 15.567788786750857
Epoca =====> 2400 Coste ====> 15.475137365989692
Epoca =====> 2500 Coste ====> 15.43218754316872
<__main__.AdalineGD at 0x7f6dd84fe8b0>
print(clf.w_)
y_pred= clf.predict(X)
print("Hecho. Número de predicciones", y_pred.shape[0])
[[ 0.35197473 0.52725999 1.82468036 -2.87215492 -1.33354983]
[ 3.73253984 0.9421312 -3.34475648 1.60896673 -4.39285218]
[-3.32555071 -3.02784207 -3.13461691 4.60395612 5.23736492]]
Hecho. Número de predicciones 150
tot_Test = y_pred.shape[0]
tot_aciertos = 0
for i in range(tot_Test):
estimado = y_pred[i]
etiqueta, = np.where(np.isclose(estimado, np.max(estimado)))
real = y[i]
if int(real) == int(etiqueta[0]):
tot_aciertos += 1
#print('Instancia %s Clase real %s Clase estimada %s - Probabilidad estimada %s \n' %(X[i], real, etiqueta[0], estimado))
print('Precisión del clasificador %s \n' %(tot_aciertos*100/tot_Test))
Precisión del clasificador 95.33333333333333
import matplotlib.pyplot as plt
marcas = ['*', 'o', 's']
clases=iris['target_names']
color = ['red', 'green', 'blue']
plt.figure(figsize=(7, 5), dpi=80)
for i in range(len(X)):
estimado = y_pred[i]
etiqueta, = np.where(np.isclose(estimado, np.max(estimado)))
ik = int(etiqueta[0])
ic = int(y[i])
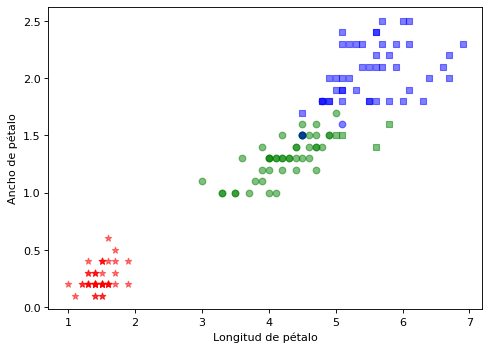
plt.scatter(X[i,2], X[i,3], c=color[ik], alpha=0.5, marker=marcas[ic])
plt.xlabel("Longitud de pétalo")
plt.ylabel("Ancho de pétalo")
plt.show()
Funciones de activación¶
Echemos un vistazo a las funciones de activación más importantes
def sigmoid(x):
#return 1.0/(1.0 + np.exp(-x)) ## versión básica con problemas de desbordamiento en valores x<<<0
#return np.where(x < 0, np.exp(x)/(1.0 + np.exp(x)), 1.0/(1.0 + np.exp(-x)))
#return 1. / (1. + np.exp(-np.clip(x, -250, 250)))
from scipy.special import expit
return expit(x) ##Función sigmoidea de scipy; algo más lenta
def sigmoid_derivada(x):
return sigmoid(x)*(1.0-sigmoid(x))
def tanh(x):
return np.tanh(x)
def tanh_derivada(x):
return 1.0 - np.tanh(x)**2
def ReLU(x):
return np.maximum(0, x)
def ReLU_derivada(x):
return np.where(x <= 0, 0, 1)
fig, axs = plt.subplots(3, 2, figsize=(15, 12))
x = np.linspace(-20, 20, 100)
axs[0][0].plot(x, sigmoid(x))
axs[0][0].set_title("sigmoidea")
axs[0][1].plot(x, sigmoid_derivada(x), 'tab:orange')
axs[0][1].set_title("sigmoidea derivada")
axs[1][0].plot(x, tanh(x), 'tab:green')
axs[1][0].set_title("tangente hiperbólica")
axs[1][1].plot(x, tanh_derivada(x), 'tab:red')
axs[1][1].set_title("tangente hiperbólica derivada")
axs[2][0].plot(x, ReLU(x))
axs[2][0].set_title("ReLU")
axs[2][1].plot(x, ReLU_derivada(x), 'tab:orange')
axs[2][1].set_title("ReLU derivada")
for ax in fig.get_axes():
ax.label_outer()
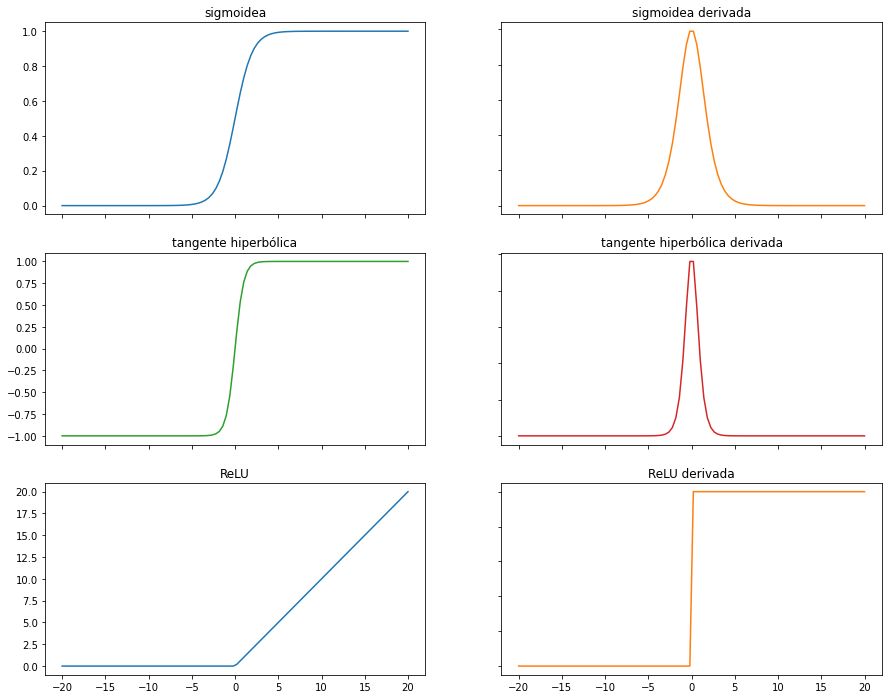
La función sigmoidea o logística:
Satura y anula el gradiente.
Lenta convergencia.
No esta centrada en el cero.
Esta acotada entre 0 y 1.
Buen rendimiento en la última capa.
La función tangente hiperbólica es muy similar a la sigmoidea:
Satura y anula el gradiente.
Lenta convergencia.
Centrada en 0.
Esta acotada entre -1 y 1.
Se utiliza para clasificaciones binarias.
Buen desempeño en redes recurrentes (que se utilizan para analizar series temporales).
La función ReLU (Rectified Lineal Unit):
Solo se activa si son positivos.
No está acotada.
Puede anular demasiadas neuronas.
Se comporta bien con imágenes.
Buen desempeño en redes convolucionales
Otra función de activación muy utilizada es Softmax que transforma las salidas a una representación en forma de probabilidades, de tal manera que el sumatorio de todas las probabilidades de las salidas de 1. Se utiliza para para normalizar tipos multiclase.
Implementación del modelo bicapa en sk-learn¶
El modelo bicapa se encuentra implementado en la clase sklearn.linear_model.Perceptron.
El constructor de la clase, por ejemplo, los siguientes parámetros:
penalty {‘l2’,’l1’,’elasticnet’}, (por defecto=None). Son los coeficientes de regularización Lasso (L1) o \(\lambda|w|\), Ridge (L2) o \(\lambda w^2\) y Elastic Net (L1 + L2). Es una manera de evitar el sobreajuste (overfitting) penalizando los altos valores de los coeficientes de regresión.
alpha : ratio de aprendizaje (por defecto 0.0001).
fit_intercept : (por defecto=True). Indica si se debe calcular el bias o ha de ser cero (datos centrados).
max_iter : (por defecto=1000). Número de épocas.
random_state: (por defecto=None). Semilla random.
tol: (por defecto 1e-3). Criterio de parada. Si no es None termina cuando coste - coste_previo < tol.
Algunos de las propiedades que se pueden consultar una vez creado el objeto con el constructor y realizado el ajuste son:
coef_, intercept_: pesos y bias.
Y los métodos más importantes son:
fit(X, y) : realiza el ajuste.
predict(X): realiza la predicción
score(X, y) : devuelve la exactitud o accuracy.
from sklearn.linear_model import Perceptron
clf = Perceptron(tol=None, max_iter=3000, alpha=0.01, random_state=0)
clf.fit(X,y)
clf.score(X,y)
0.8933333333333333