Cadenas de Markov absorbentes en Sage
Presentado por Javier Sanz-Cruzado y Pablo Angulo en las III Jornadas Sage/Python celebradas en la Universidade de Vigo los días 21 y 22 de Junio de 2012.
4 Matemáticos quieren colaborar
- 4 matemáticos en un departamento.
- Cada uno trabaja en un área distinta (Geometría, Análisis, Topología, Estadística).
- Deciden seguir el siguiente esquema:
- Cada noche juegan a las cartas, y como resultado hay un ganador y un perdedor.
- El perdedor se pasa al área del ganador.
- Cuando los cuatro trabajen en el mismo área, escriben un artículo, y vuelven a empezar.
Ref: Markov Chains for Collaboration (Robert Mena y Will Murray), Mathematics Magazine
Ejemplo
(Fulano) Geometría, (Mengano) Análisis, (Zutano) Topología, (Renano) Estadística
Noche 1: Fulano gana, Renano pierde
(Fulano y Renano) Geometría, (Mengano) Análisis, (Zutano) Topología, Estadística
Noche 2: Mengano gana, Fulano pierde
(Fulano y Mengano) Análisis, (Renano) Geometría, (Zutano) Topología, Estadística
Noche 3: Mengano gana, Zutano pierde
(Fulano, Mengano y Zutano) Análisis, (Renano) Geometría, Topología, Estadística
Noche 4: Mengano gana, Fulano pierde
(Fulano, Mengano y Zutano) Análisis, (Renano) Geometría, Topología, Estadística
Noche 5: Zutano gana, Renano pierde
(Fulano, Mengano, Zutano y Renano) Análisis, Geometría, Topología, Estadística
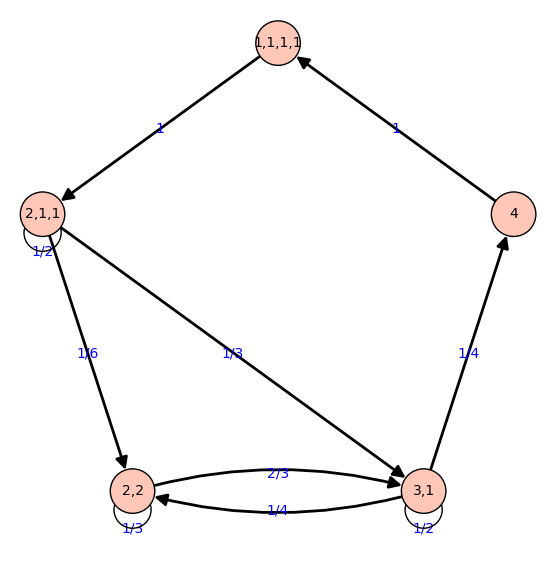
Modelizando
Modelizamos el proceso con una cadena de Markov.
Nos fijamos sólo en cuántas áreas distintas quedan, y cuantas personas trabajan en cada área: Particiones de 4.
Ejemplo: En el estado (2,1,1) tenemos cuatro matemáticos trabajando en tres áreas: ((1,2), (3), (4))
- Escogemos un ganador y un perdedor: 14⋅(4−1)
14⋅(4−1) posibilidades. Por ejemplo, gana 4 y pierde 2. - Sumamos 1 miembro al equipo del ganador y restamos 1 al del perdedor. Por ejemplo, pasamos a (1,1,2)
- Ordenamos y eliminamos los equipos vacíos. En el ejemplo, pasamos a (2,1,1)
Noche 2: Mengano gana, Fulano pierde
|
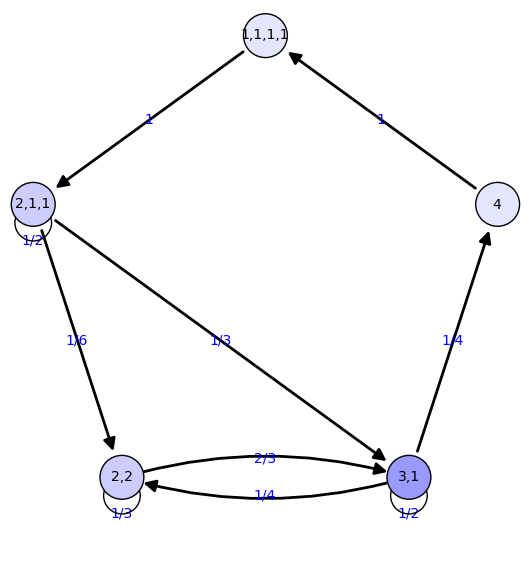
Distribución de probabilidad estable
En el campo de cadenas de Markov, suele ser interesante la distribución de probabilidad estable.
Pero, ¿qué significa en este caso?
Mejor aún, ¿qué preguntas queremos responder?
Quizá la pregunta más obvia es:
¿Cuánto tiempo tardan en ponerse de acuerdo sobre el área en la que van a trabajar?
Si hacemos el cálculo...
|
|
{'2,2': 1/5, '4': 1/10, '1,1,1,1': 1/10, '3,1': 2/5, '2,1,1': 1/5}
|
Tiempo medio que dura el proceso
- Los caminos aleatorios que comienzan en (1,1,1,1) eventualmente llegan a (4).
- Desde (4) pasan a (1,1,1,1) y se repite el proceso.
- La probabilidad estable del vértice (4) es 1/10.
- Esto siginifica que los caminos aleatorios pasan la décima parte del tiempo pasando de (4) a (1,1,1,1) (una sóla noche)
- El resto del tiempo, lo pasan viajando del (1,1,1,1) al (4).
- Luego el viaje del (1,1,1,1) al (4) dura en promedio 9 noches.
Pero con este truco sólo sacamos el tiempo medio. Ésta no es la forma adecuada de estudiar el problema.
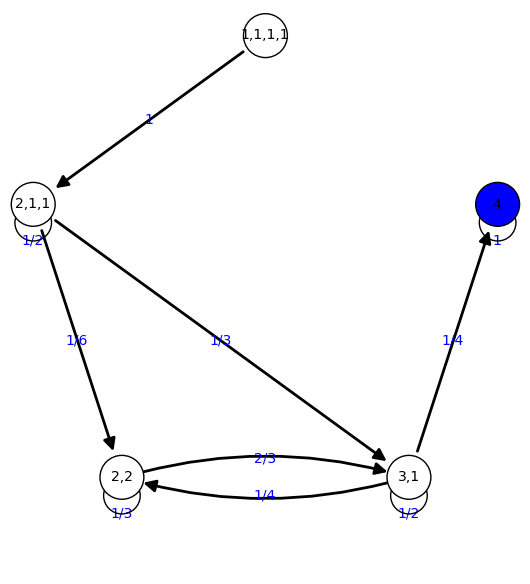
Cadenas de Markov absorbentes
- Uno (o varios) estados terminales.
- Si sólo hay un estado terminal, la probabilidad estable es trivial!
Modificamos el ejemplo anterior: al llegar al estado (4), nos quedamos allí indefinidamente.
|
|
{'2,2': 0, '4': 1, '1,1,1,1': 0, '3,1': 0, '2,1,1': 0}
|
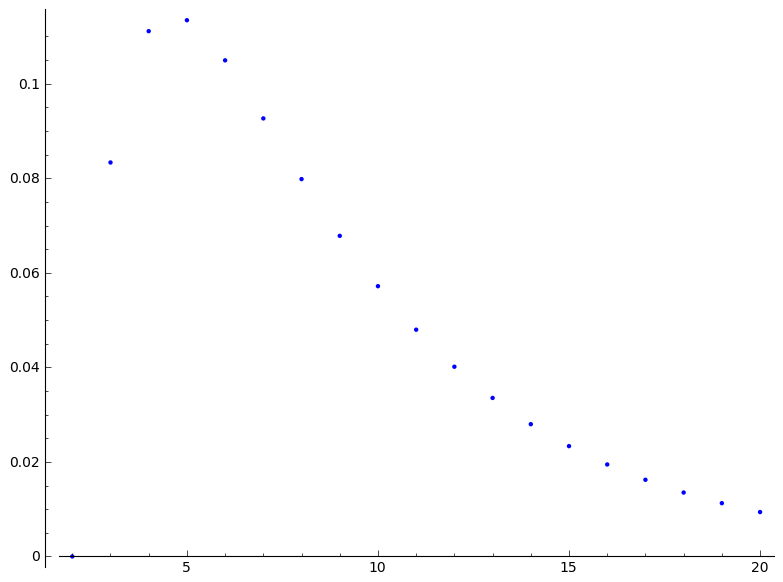
Ahora podemos calcular la probabilidad de que el proceso termine antes de tiempo k:
Es la entrada en la primera fila y última columna de la matriz M^k!
0 {'2,2': 0.000, '4': 0.000, '1,1,1,1': 1.00, '3,1': 0.000, '2,1,1':
0.000}
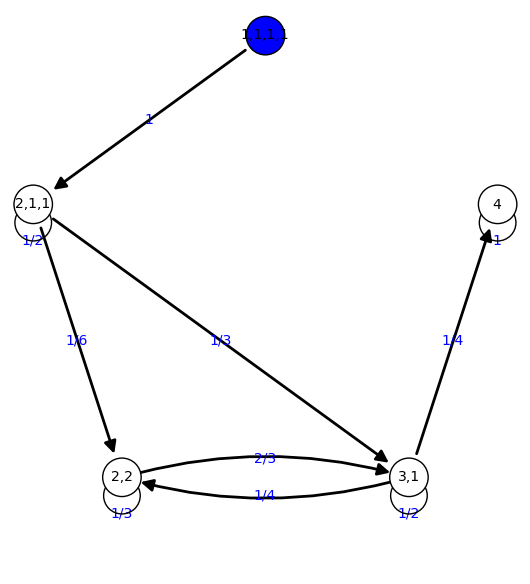 1 {'2,2': 0.000, '4': 0.000, '1,1,1,1': 0.000, '3,1': 0.000,
'2,1,1': 1.00}
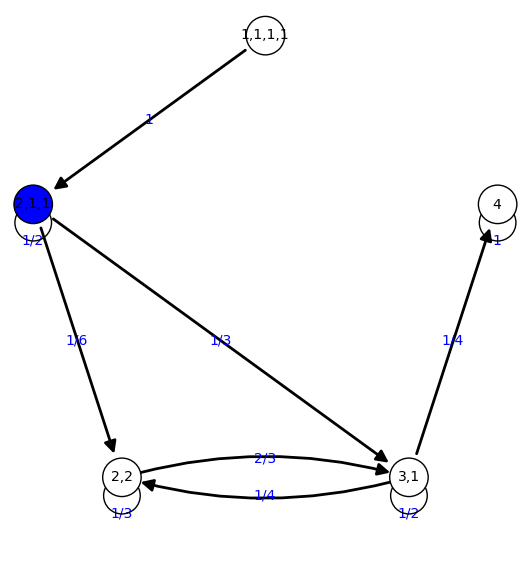 2 {'2,2': 0.167, '4': 0.000, '1,1,1,1': 0.000, '3,1': 0.333,
'2,1,1': 0.500}
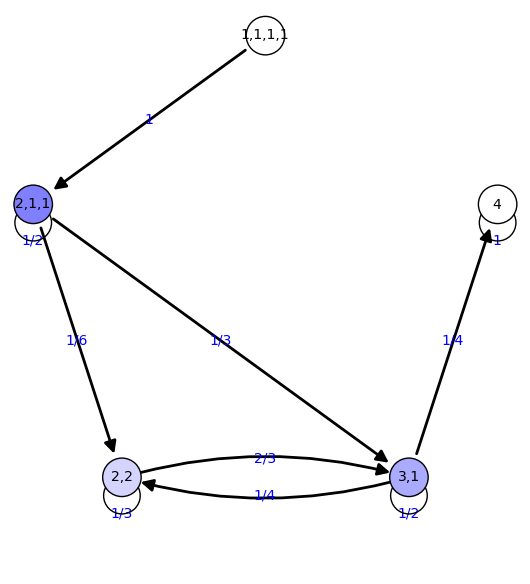 3 {'2,2': 0.222, '4': 0.0833, '1,1,1,1': 0.000, '3,1': 0.444,
'2,1,1': 0.250}
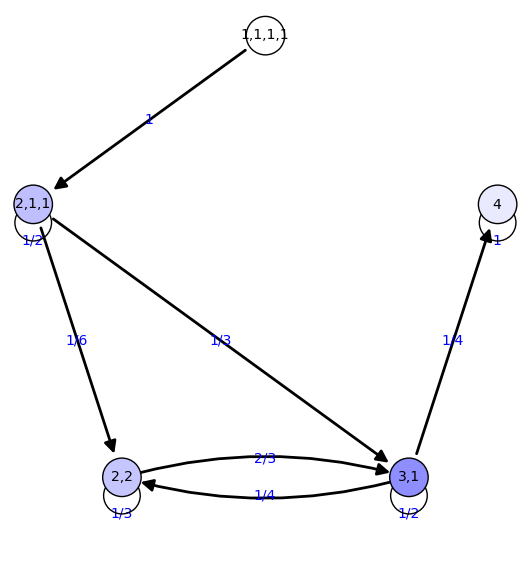 4 {'2,2': 0.227, '4': 0.194, '1,1,1,1': 0.000, '3,1': 0.454,
'2,1,1': 0.125}
 5 {'2,2': 0.210, '4': 0.308, '1,1,1,1': 0.000, '3,1': 0.420,
'2,1,1': 0.0625}
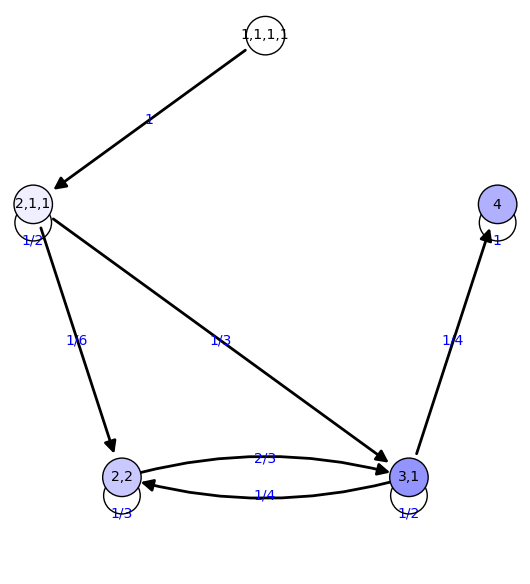 6 {'2,2': 0.185, '4': 0.413, '1,1,1,1': 0.000, '3,1': 0.371,
'2,1,1': 0.0312}
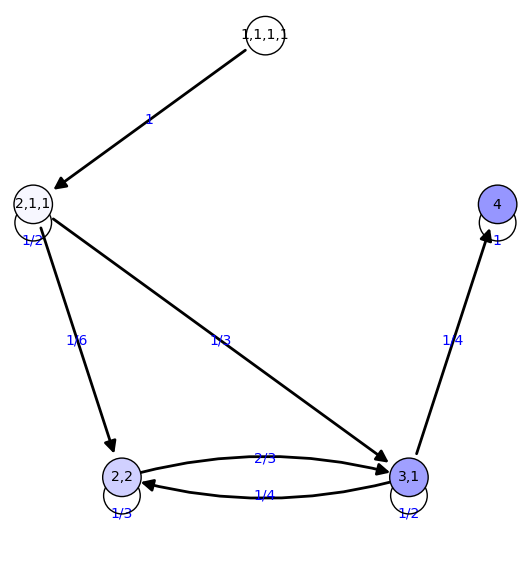 7 {'2,2': 0.160, '4': 0.505, '1,1,1,1': 0.000, '3,1': 0.319,
'2,1,1': 0.0156}
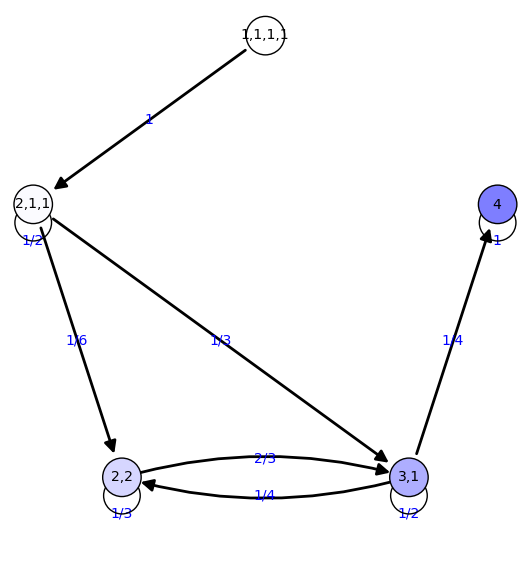 8 {'2,2': 0.136, '4': 0.585, '1,1,1,1': 0.000, '3,1': 0.271,
'2,1,1': 0.00781}
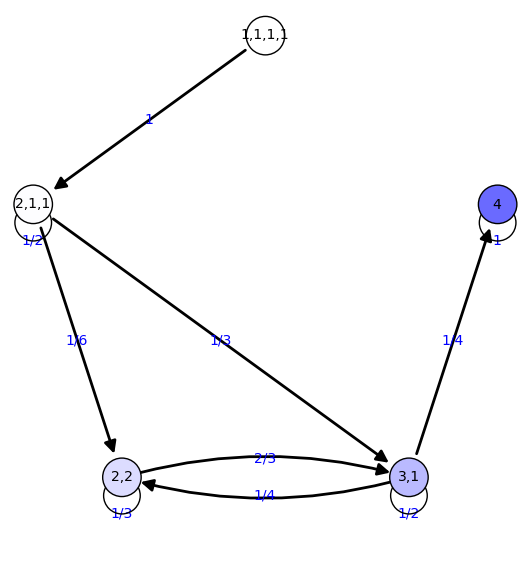
|
|
|
Representamos la convergencia en forma de animaciones:
- Representación en forma de grafo
|
|
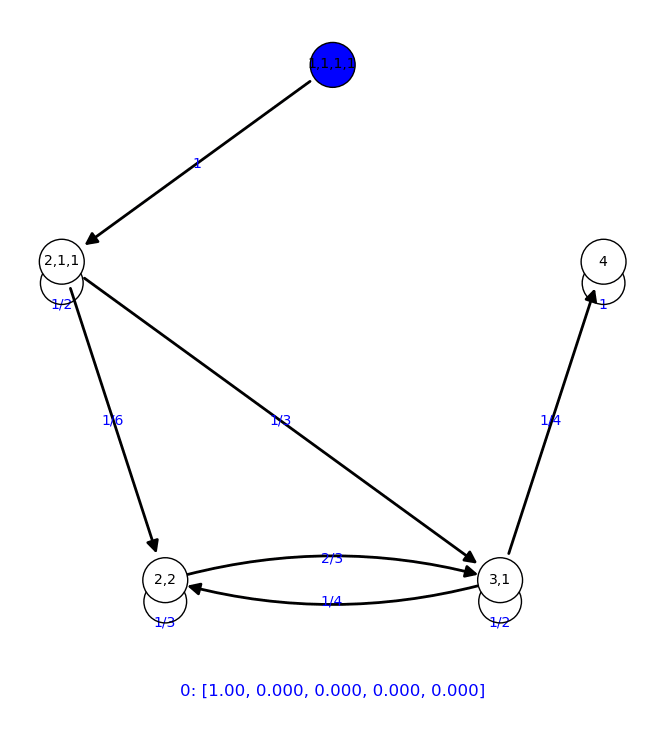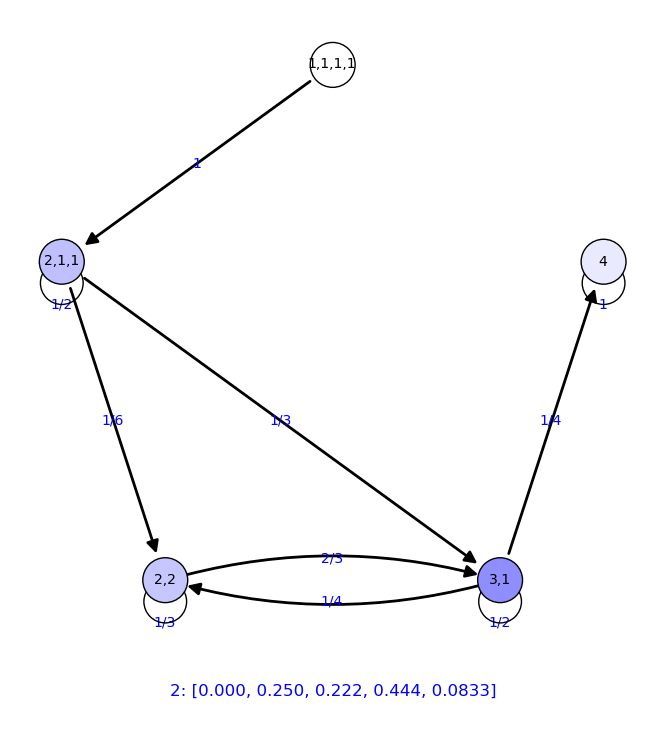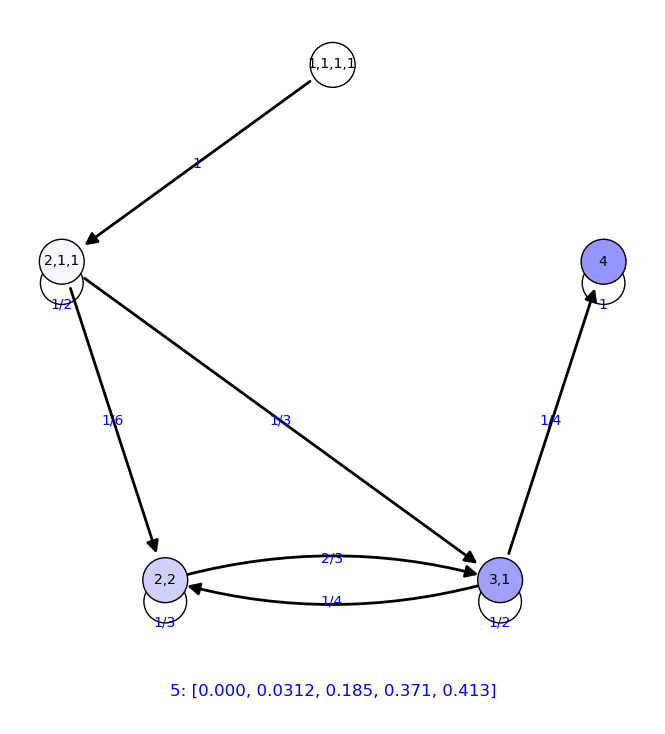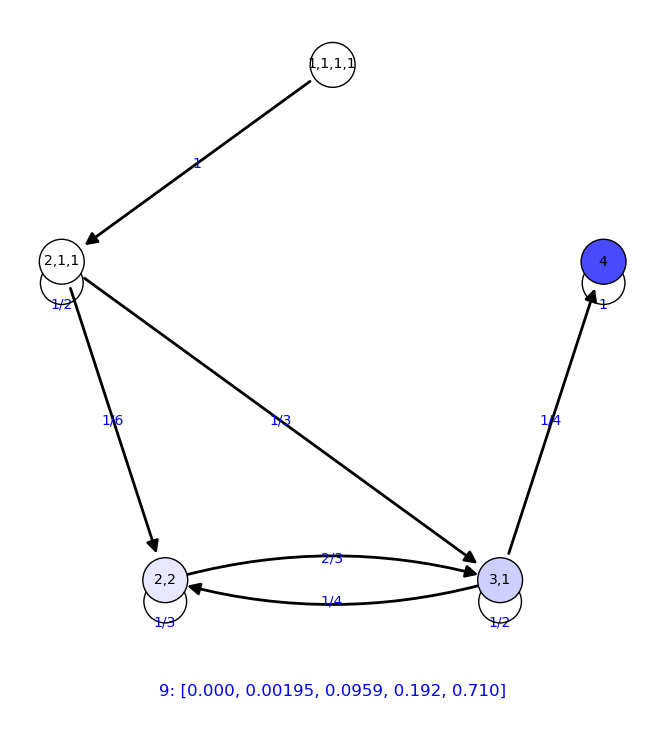
|
Otra representación interesante usando Matrix Plot
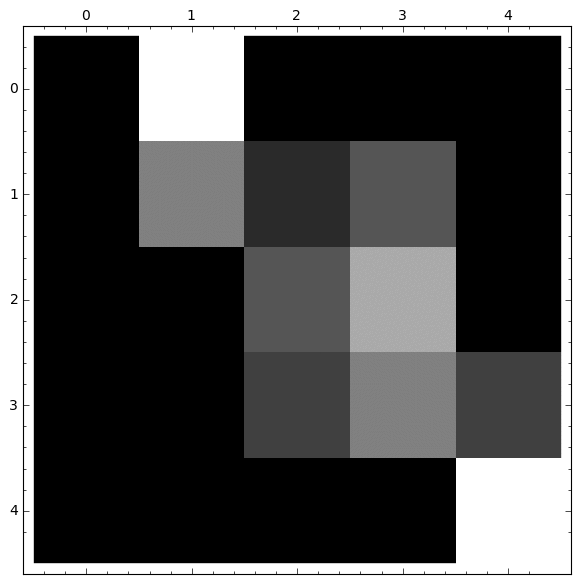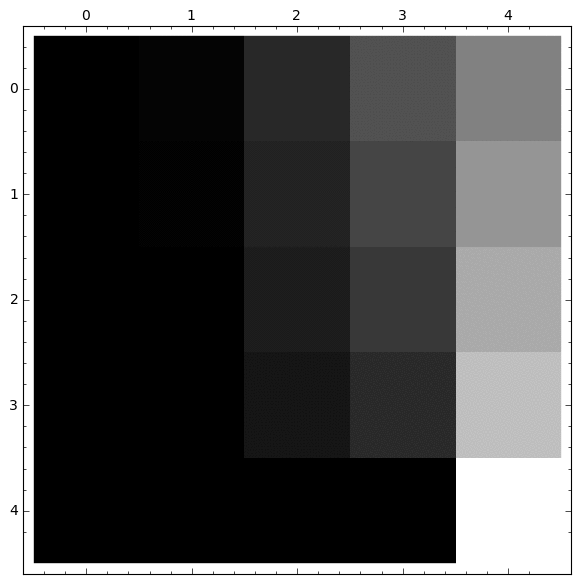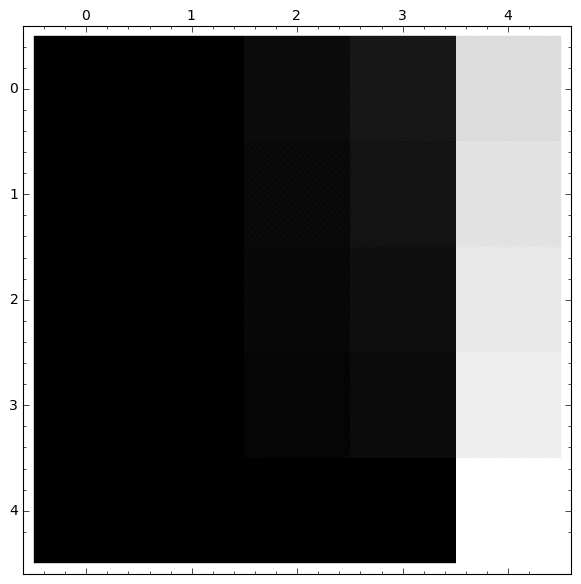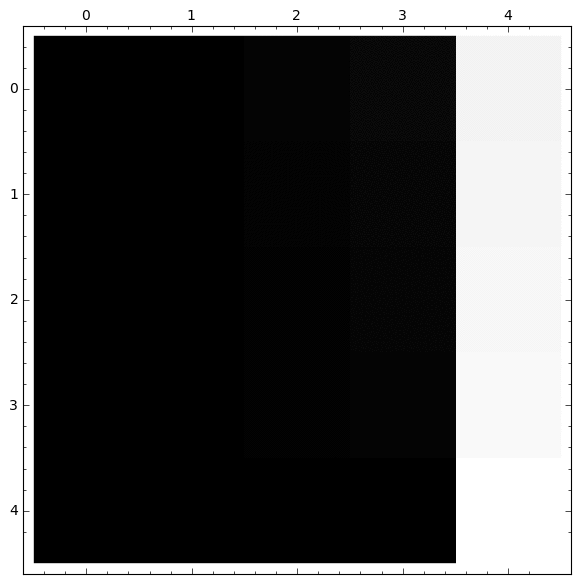
|
Distribución del tiempo de llegada
... usamos una variable simbólica k
Problema: No se puede elevar una matriz a un exponente directamente
Traceback (click to the left of this block for traceback) ... NotImplementedError: non-integral exponents not supported |
Así que usamos la ténica aprendida en Álgebra Lineal:
Mk=P⋅Dk⋅P−1
donde M=P⋅D⋅P−1
Por el momento asumimos que la matriz es diagonalizable.
|
(02(12)k−(12)k+35(56)k−2(12)k+65(56)k(12)k−95(56)k+10(12)k−12(12)k+12(56)k−(12)k+(56)k12(12)k−32(56)k+10025(56)k45(56)k−65(56)k+100310(56)k35(56)k−910(56)k+100001)
|
La prob que nos interesa es ...
(1/2)^k - (1/2)^(k - 1) - 9/5*(5/6)^k + 9/5*(5/6)^(k - 1) |
Ojo! pcum(k=0) es incorrecto
luego p(k=1) es incorrecto
Sabemos que p(k=1)=0!
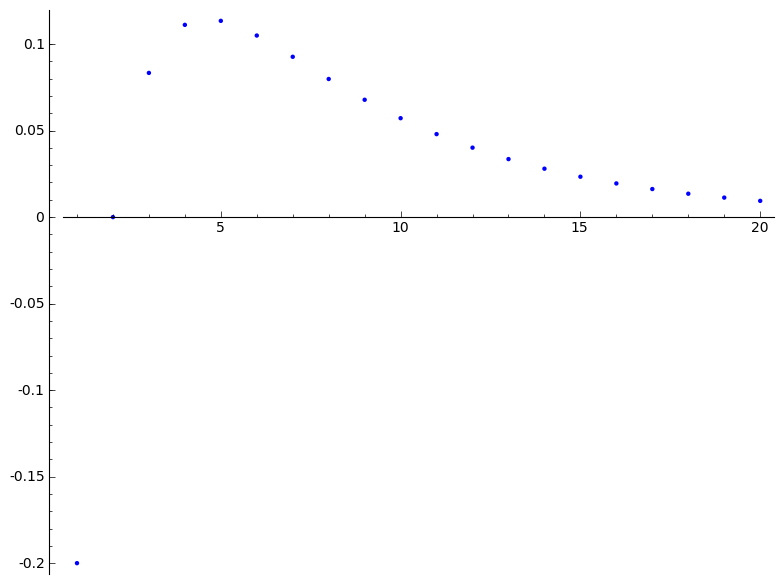
|
- La fórmula que hemos usado no funciona cuando k<=0
- La matriz M es singular!
- La técnica anterior funciona para k<=0 si y sólo si la matriz es no singular.
1 :(010000121613000132300014121400001) 0 :(1000001000001000001000001) -1 : Traceback (click to the left of this block for traceback) ... ZeroDivisionError: input matrix must be nonsingular |
Afortunadamente, la solución es sencilla: no necesitamos trabajar con k0=0.
|
Ahora podríamos calcular la media, varianza...
pero Sage dice que no sabe!
-1/25*sum(-(9*2^k*5^k - 25*6^k)*2^(-k)*6^(-k), k, 2, +Infinity) |
Sin embargo, sabe sumar las partes de p:
3/2 -1/2 |
Así que le ayudamos, expandiendo la expresión simbólica, y luego sumando cada sumando por separado.
Probabilidad total: 1 Media: 9 Varianza: 32 |
Cálculo directo del tiempo medio
Buscamos ahora otro método para calcular el tiempo medio.
EXi
Queremos resolver un sistema de ecuaciones lineales, con ecuaciones del tipo
EXi=1+p(Ir al nodo a)·EXa+p(Ir al nodo b)·EXb....
para un estado i
EXi=0
para un estado i
El sistema en forma matricial
Sea E
(EX1,…,EXN)
E
E⋅A=v
donde
A→
- Si el vértice i-ésimo no es absorbente
- 1−M[i][i]
1−M[i][i] en la posición i-ésima (M→M→ Matriz probabilidades de transición) - −M[i][j]
−M[i][j] en el resto
- 1−M[i][i]
- Si el vértice i-ésimo es absorbente
- 1 en la posición i
- 0 en el resto
v→
- 1 si el vértice i-ésimo no es absorbente
- 0 si el vértice i-ésimo es absorbente
|
(1−1000012−16−1300023−23000−1412−1400001)
Tiempo medio en llegar al estado absorbente 1,1,1,1 : 9 2,1,1 : 8 2,2 : 7 3,1 : 11/2 4 : 0 |
El tiempo medio partiendo del estado (1,1,1,1) se corresponde con el calculado anteriormente.
Araña en un cubo
- Tenemos una araña en un vértice de un cubo
- Tenemos veneno en dos vértices del cubo
- La araña se mueve siguiendo las aristas del cubo, de un vértice a otro
- Si llega a un vértice con veneno, muere.
Buscamos saber cual es la probabilidad de que muera en un vértice u en otro según el vértice del que parta la araña
Ejemplo
Tenemos que los venenos se hallan en los vértices 2 y 5
Tenemos una cadena de Markov absorbente con varios estados terminales
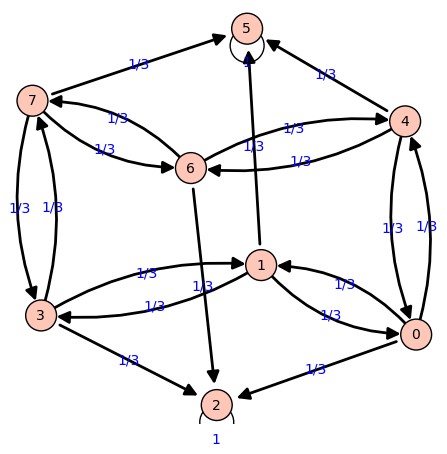
|
Ejemplo partiendo la araña del vértice 0
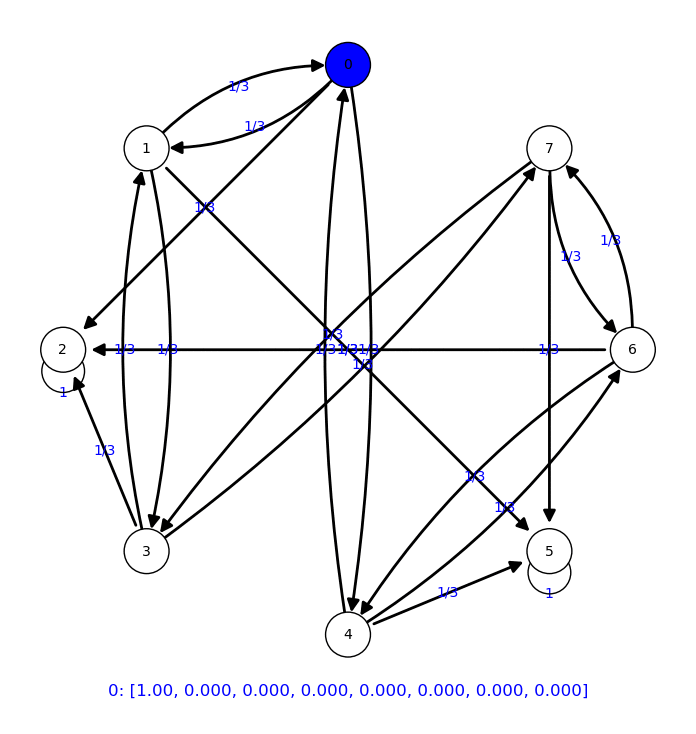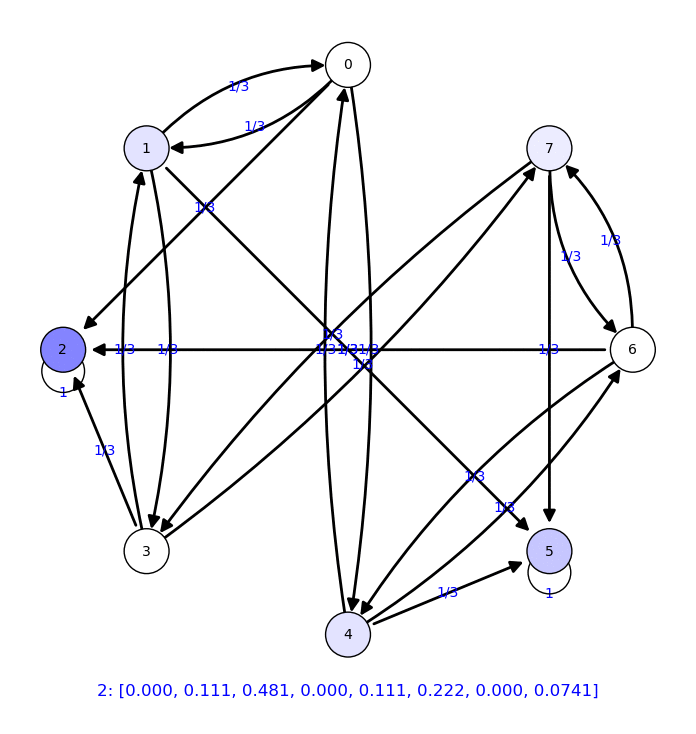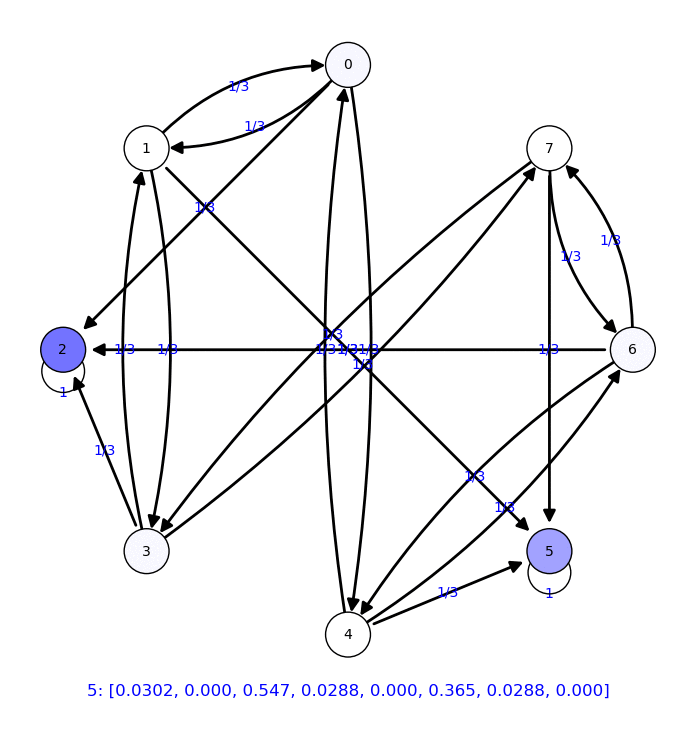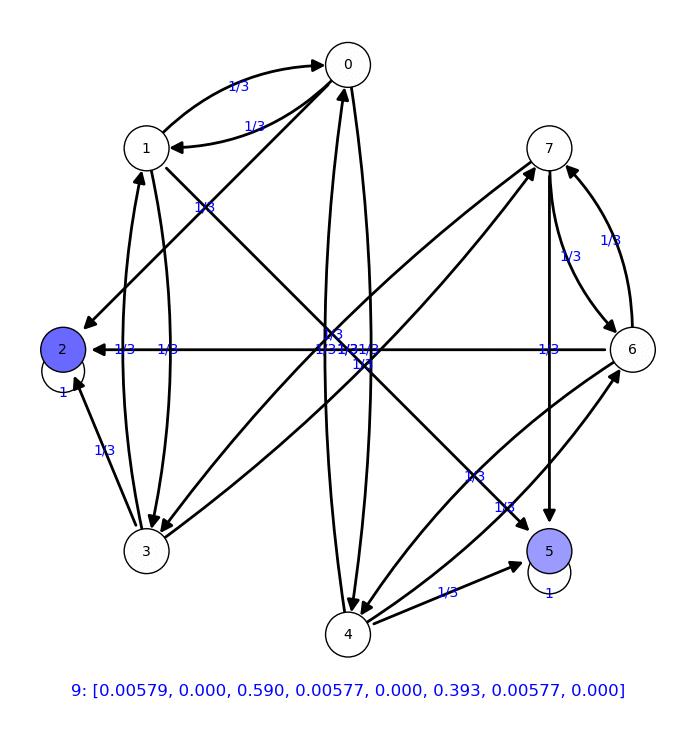
|
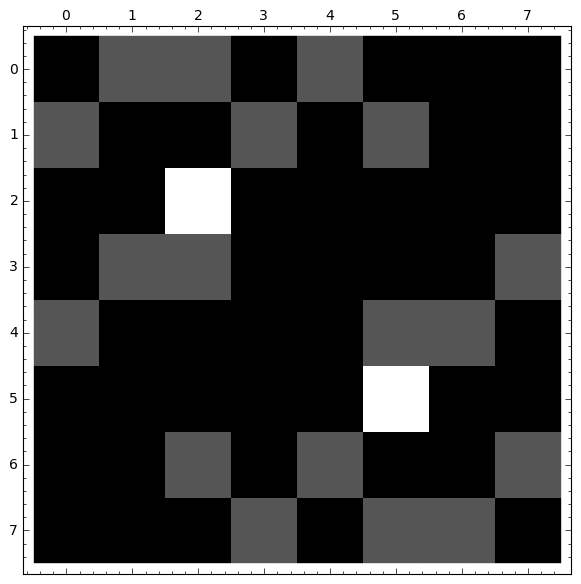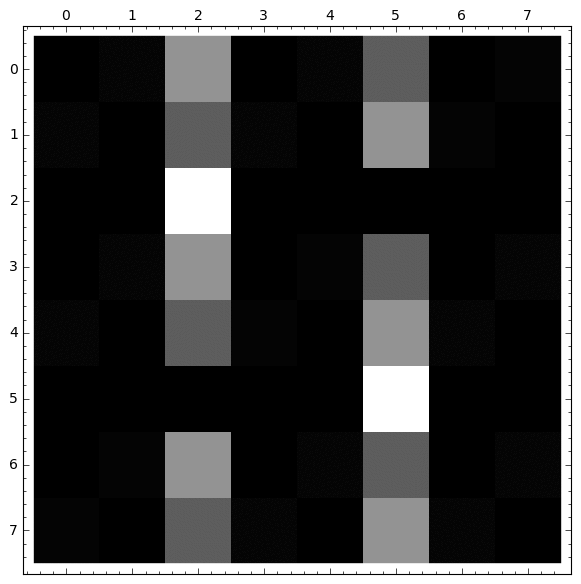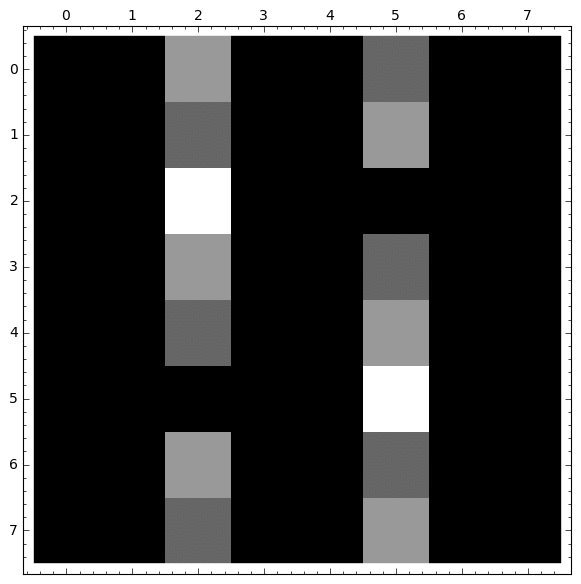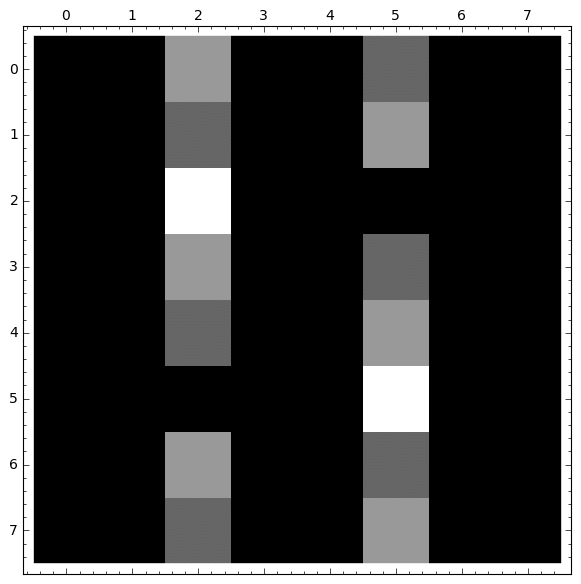
|
En este caso, la distribución de probabilidad estable no es trivial: Se reparte entre los diferentes estados absorbentes.
Vamos a calcular estas probabilidades para cada vértice inicial:
- pX(vY)→
pX(vY)→ Probabilidad de llegar al veneno X desde el vértice Y
Las ecuaciones ahora serán del tipo: pX(v0)=pX(v0)·p(Llegar a v0)+pX(v1)·p(Llegar a v1)+...
para un estado no absorbente y para los estados absorbentes sabemos que:
- pVen1(vVen1)=pVen2(vVen2)=1
pVen1(vVen1)=pVen2(vVen2)=1 - pVen1(vVen2)=pVen2(vVen1)=0
pVen1(vVen2)=pVen2(vVen1)=0
El sistema en forma matricial
Sea P
(pX(v1),…,pX(vN))
P
P⋅A=v
donde
A→
- Si el vértice i-ésimo no es absorbente
- 1−M[i][i]
1−M[i][i] en la posición i-ésima (M→M→ Matriz de transición) - −M[i][j]
−M[i][j] en el resto
- 1−M[i][i]
- Si el vértice i-ésimo es absorbente
- 1 en la posición i
- 0 en el resto
v→
- 1 si el vértice i-ésimo es el vértice absorbente al que queremos llegar
- 0 para el resto
Por ejemplo, calculamos la probabilidad de morir en el veneno 1:
PROBABILIDAD DE CAER EN VENENO 1 Matriz del sistema(1−13−130−13000−1310−130−1300001000000−13−131000−13−130001−13−1300000010000−130−1301−13000−130−13−131) Terminos independientes del sistema(0,0,1,0,0,0,0,0) Solucion del sistema 0 : 3/5 1 : 2/5 2 : 1 3 : 3/5 4 : 2/5 5 : 0 6 : 3/5 7 : 2/5 |
Para el veneno 2, tenemos que:
pVen2(vi)=1−pVen1(vi)
Tiempo medio en morir
Calculamos con la técnica anterior el tiempo medio en morir (es decir, en llegar a uno de los dos estados absorbentes).
TIEMPO MEDIO EN MORIR Matriz del sistema(1−13−130−13000−1310−130−1300001000000−13−131000−13−130001−13−1300000010000−130−1301−13000−130−13−131) Terminos independientes del sistema(1,1,0,1,1,0,1,1) Solucion del sistema 0 : 3 1 : 3 2 : 0 3 : 3 4 : 3 5 : 0 6 : 3 7 : 3 |
La misma técnica funciona para cualquier grafo absorbente.
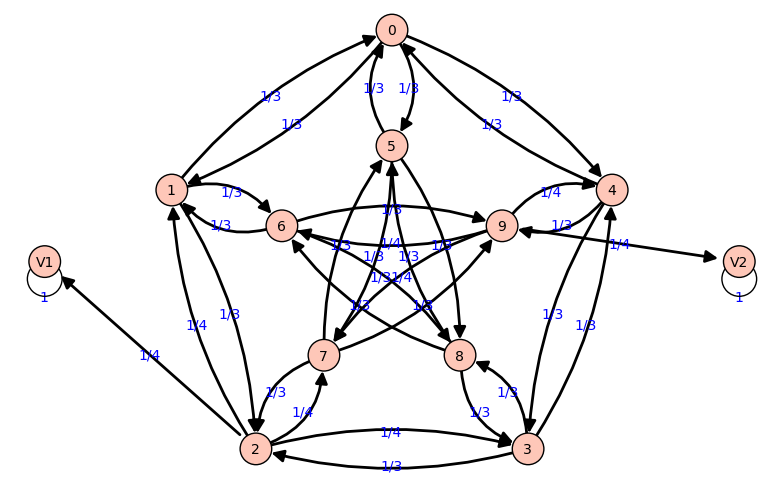
|
PROBABILIDAD DE CAER EN VENENO 2
[(0, 1/2), (1, 13/28), (2, 5/14), (3, 13/28), (4, 15/28), (5, 1/2),
(6, 15/28), (7, 1/2), (8, 1/2), (9, 9/14), ('V1', 0), ('V2', 1)]
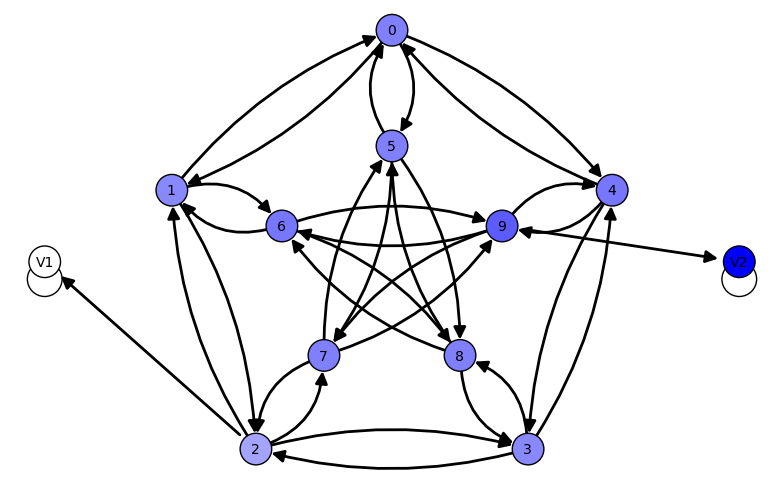
|
|
|
Tiempo de llegada infinito
¿Qué ocurriría si la probabilidad de no llegar a alguno de los venenos fuese >0?
En este caso, el grafo no es absorbente.
Hemos de estudiar:
- Probabilidad de llegar a cada veneno
- Tiempo medio
PROBABILIDAD DE LLEGAR A CADA VENENO
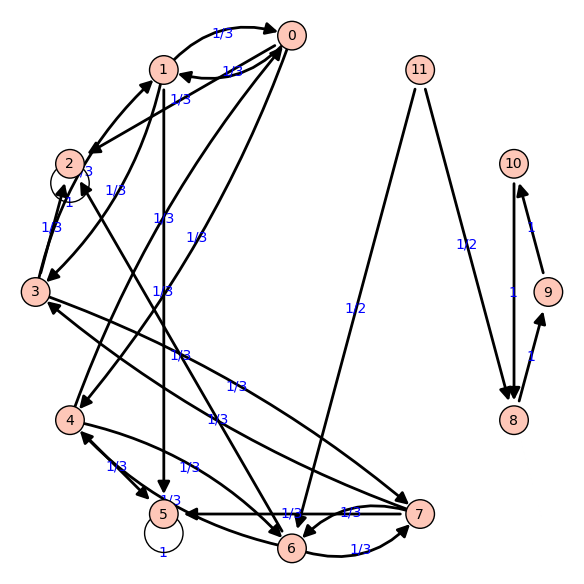
|
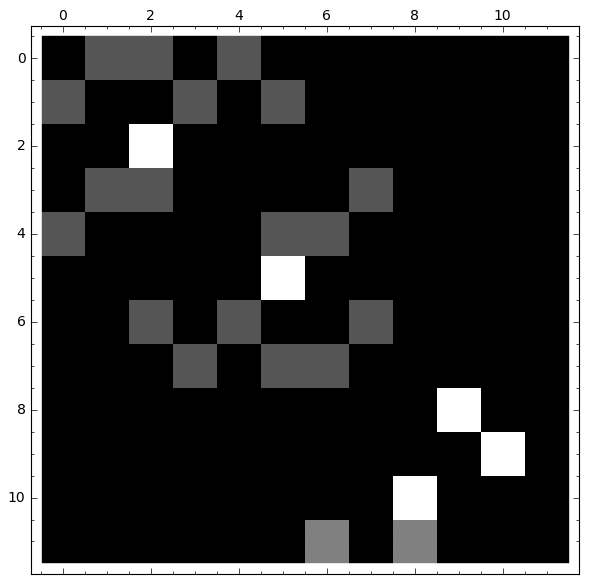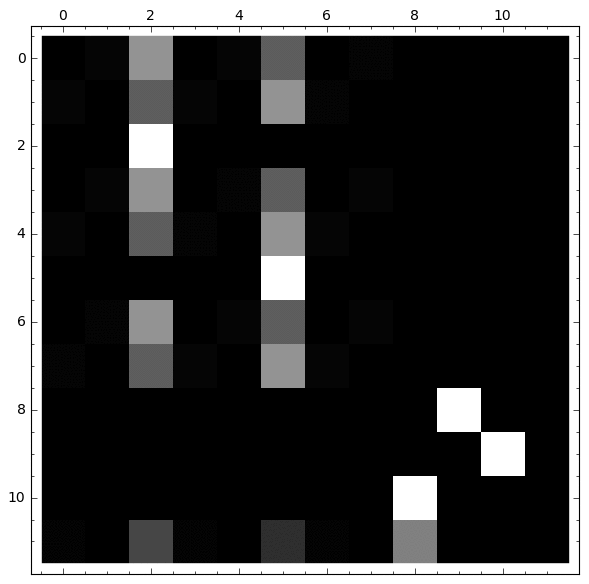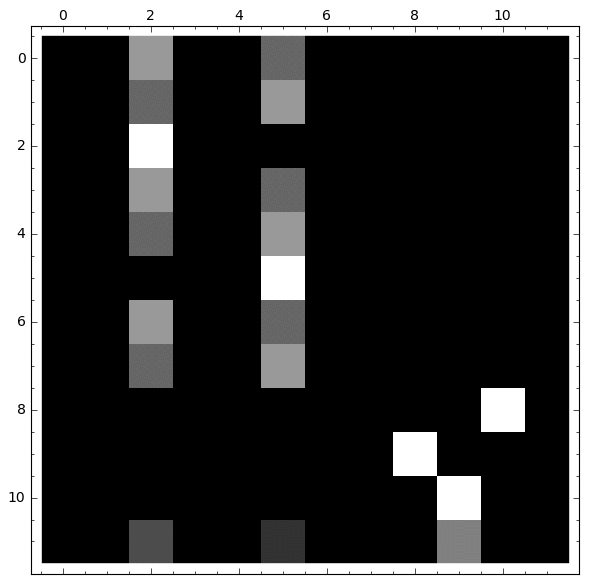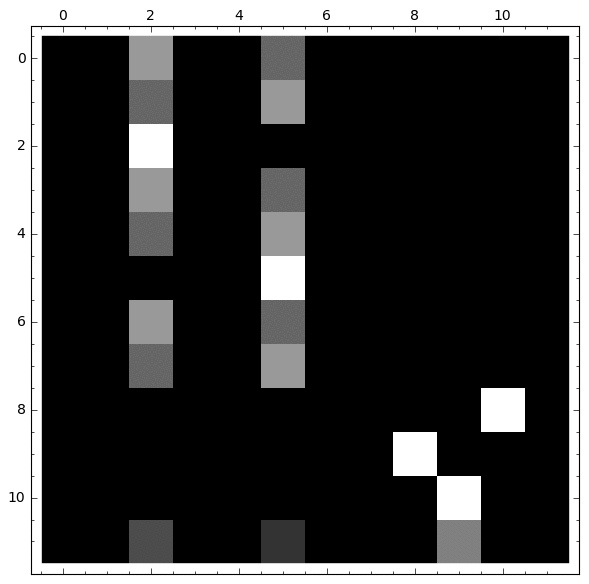
|
Observamos que:
- Si partimos de cualquier nodo del 1 al 7, la probabilidad de caer en el veneno se estabiliza
- Si partimos de los nodos 8, 9 o 10, la probabilidad no se estabiliza
- p(Llegar a algun veneno) = 0
- Si partimos del vértice 11, la probabilidad en los nodos con veneno se estabiliza, mientras que no ocurre lo mismo en el bucle.
- p1(v11)+p2(v11)<1
p1(v11)+p2(v11)<1
- p1(v11)+p2(v11)<1
|
|
PROBABILIDAD DE CAER EN EL VENENO 1 Matriz del sistema(1−13−130−130000000−1310−130−130000000010000000000−13−131000−130000−130001−13−130000000000100000000−130−1301−130000000−130−13−1310000000000001−1000000000001−1000000000−1010000000−120−12001) Terminos independientes del sistema(0,0,1,0,0,0,0,0,0,0,0,0) Solucion del sistema 0 : 3/5 1 : 2/5 2 : 1 3 : 3/5 4 : 2/5 5 : 0 6 : 3/5 7 : 2/5 8 : -3/5 9 : -3/5 10 : -3/5 11 : 0 |
¡Nos encontramos un problema!
Las ecuaciones
pVen1(8)=pVen1(9)
pVen1(9)=pVen1(10)
pVen1(10)=pVen1(8)
no tienen solución
Determinante: 0 Vector space of degree 12 and dimension 1 over Rational Field Basis matrix: [ 0 0 0 0 0 0 0 0 1 1 1 1/2] |
Sin embargo, sabemos que en estos vértices la probabilidad de llegar al veneno es 0.
Hemos de modificar el sistema. ¿Cómo detectamos estos vértices?
Idea: Distancias entre nodos del grafo
2 +Infinity |
Tenemos que:
- d(vi,vVenenoX)=∞⇔pX(vi)=0
d(vi,vVenenoX)=∞⇔pX(vi)=0
Por tanto, modificamos el sistema para tratar con estos problemas:
Para el estado absorbente objetivo:
pX(X)=1
Para otro estado absorbente vi
pX(vi)=0
Si d(vi,vVenenoX)=∞
pX(vi)=0
Si d(vi,vVenenoX)<∞
pX(vi)=pX(v0)·p(Llegar a v0)+pX(v1)·p(Llegar a v1)+...
|
|
|
|
VENENO 1 Matriz del sistema(1−13−130−130000000−1310−130−130000000010000000000−13−131000−130000−130001−13−130000000000100000000−130−1301−130000000−130−13−1310000000000001000000000000100000000000010000000−120−12001) Terminos independientes(0,0,1,0,0,0,0,0,0,0,0,0) Solucion del sistema 0 : 3/5 1 : 2/5 2 : 1 3 : 3/5 4 : 2/5 5 : 0 6 : 3/5 7 : 2/5 8 : 0 9 : 0 10 : 0 11 : 3/10 VENENO 2 Matriz del sistema(1−13−130−130000000−1310−130−130000000010000000000−13−131000−130000−130001−13−130000000000100000000−130−1301−130000000−130−13−1310000000000001000000000000100000000000010000000−120−12001) Terminos independientes(0,0,0,0,0,1,0,0,0,0,0,0) Solucion del sistema 0 : 2/5 1 : 3/5 2 : 0 3 : 2/5 4 : 3/5 5 : 1 6 : 2/5 7 : 3/5 8 : 0 9 : 0 10 : 0 11 : 1/5 SUMA p1(v0) + p2(v0) = 1.000000 p1(v1) + p2(v1) = 1.000000 p1(v2) + p2(v2) = 1.000000 p1(v3) + p2(v3) = 1.000000 p1(v4) + p2(v4) = 1.000000 p1(v5) + p2(v5) = 1.000000 p1(v6) + p2(v6) = 1.000000 p1(v7) + p2(v7) = 1.000000 p1(v8) + p2(v8) = 0.000000 p1(v9) + p2(v9) = 0.000000 p1(v10) + p2(v10) = 0.000000 p1(v11) + p2(v11) = 0.500000 |
TIEMPO MEDIO
Empleando lo anterior, tenemos que:
- d(vi,vVenenoX)=∞⇒pX(vi)=0⇒EXi=∞
d(vi,vVenenoX)=∞⇒pX(vi)=0⇒EXi=∞
Además:
- Si d(vi,vj)≠∞
d(vi,vj)≠∞ donde d(vj,vVenenoX)=∞d(vj,vVenenoX)=∞ , entonces EXi=∞EXi=∞
Calculamos estos vértices:
|
|
Vertices seguros: [8, 9, 10] Vertices con media infinita: [8, 9, 10, 11] |
Con esta función, y el sistema de ecuaciones empleado anteriormente, calcularemos de nuevo el tiempo medio
|
|
TIEMPO MEDIO Matriz del sistema(1−13−130−130000000−1310−130−130000000010000000000−13−131000−130000−130001−13−130000000000100000000−130−1301−130000000−130−13−1310000000000001000000000000100000000000010000000−120−12001) Terminos independientes(1,1,0,1,1,0,1,1,1,1,1,1) Solucion del sistema 0 : 3 1 : 3 2 : 0 3 : 3 4 : 3 5 : 0 6 : 3 7 : 3 8 : +Infinity 9 : +Infinity 10 : +Infinity 11 : +Infinity |
|
|
|
|
Lanzamiento de monedas
- Tenemos una moneda no lastrada
- Lanzamos la moneda hasta obtener cuatro caras
¿Cuántas veces hay que lanzar la moneda para obtener cuatro caras?
Dos formas de solucionar el problema:
- Distribución binomial negativa
- Usando una Cadena de Markov
Usando cadenas de Markov
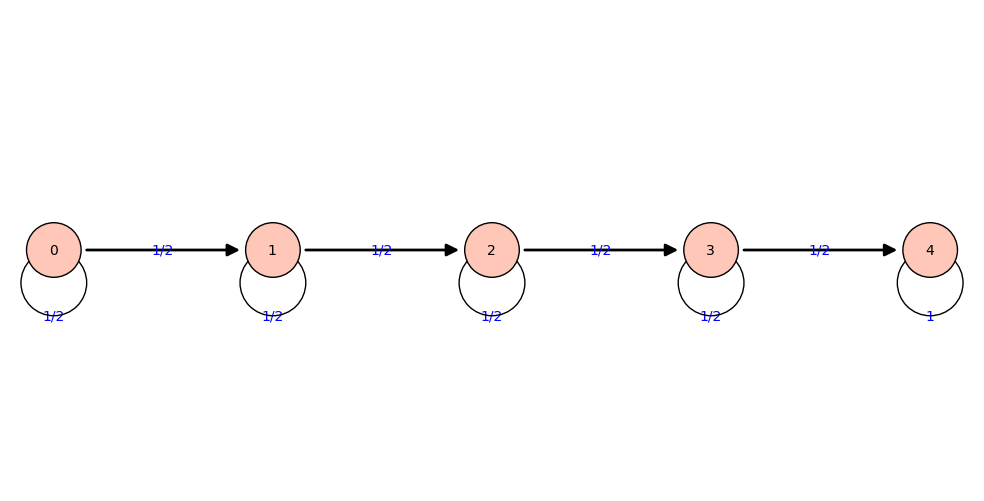
|
Observamos la evolución de la distribución:

|
|
(121200001212000012120000121200001)
[ 1| 0 0 0 0] [---+---------------] [ 0|1/2 1 0 0] [ 0| 0 1/2 1 0] [ 0| 0 0 1/2 1] [ 0| 0 0 0 1/2] |
Observamos que la matriz de transición no es diagonalizable.
Tenemos que construir una nueva función para elevar cualquier matriz de Jordan a una variable simbólica
|
|
|
(100000(12)kk(12)(k−1)12(k−1)k(12)(k−2)16(k−2)(k−1)k(12)(k−3)00(12)kk(12)(k−1)12(k−1)k(12)(k−2)000(12)kk(12)(k−1)0000(12)k)
|
|
((12)k12k(12)(k−1)18(k−1)k(12)(k−2)148(k−2)(k−1)k(12)(k−3)−148(k−2)(k−1)k(12)(k−3)−18(k−1)k(12)(k−2)−12k(12)(k−1)−(12)k+10(12)k12k(12)(k−1)18(k−1)k(12)(k−2)−18(k−1)k(12)(k−2)−12k(12)(k−1)−(12)k+100(12)k12k(12)(k−1)−12k(12)(k−1)−(12)k+1000(12)k−(12)k+100001)
|
Hallamos la media y la varianza
(1/2)^(k - 1) + 1/48*(k - 3)*(k - 2)*(k - 1)*(1/2)^(k - 4) - 1/48*(k - 2)*(k - 1)*k*(1/2)^(k - 3) + 1/8*(k - 2)*(k - 1)*(1/2)^(k - 3) - 1/8*(k - 1)*k*(1/2)^(k - 2) + 1/2*(k - 1)*(1/2)^(k - 2) - 1/2*k*(1/2)^(k - 1) - (1/2)^k |
Probabilidad total: 1 Media: 8 Varianza: 8 |
|
|
|
|
Distribución Binomial Negativa
Comparamos con la distribución del tiempo de llegada con la distribución de probabilidad binomial negativa
f(k)≡Pr(X=k)=(k−1k−r)(1−p)rpk−rfor k=r,r+1,r+2,…,
1/3*(k^3 - 6*k^2 + 11*k - 6)*2^(-k - 1) |
1/3*(k^3 - 6*k^2 + 11*k - 6)*2^(-k - 1) |
|
|
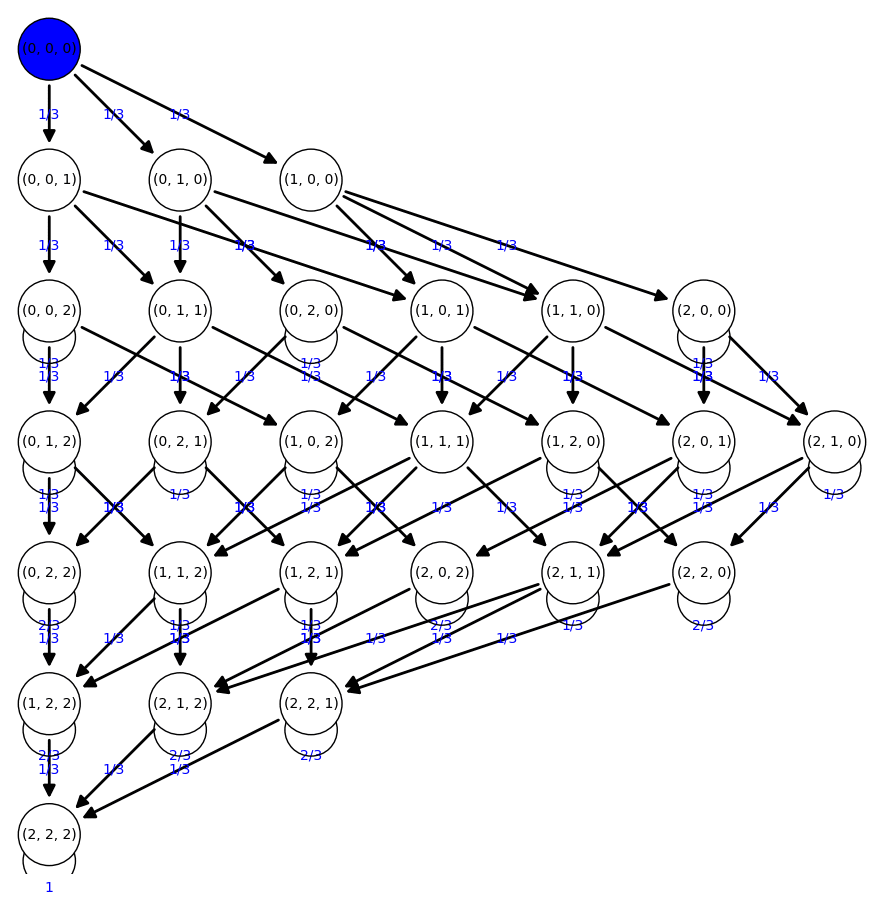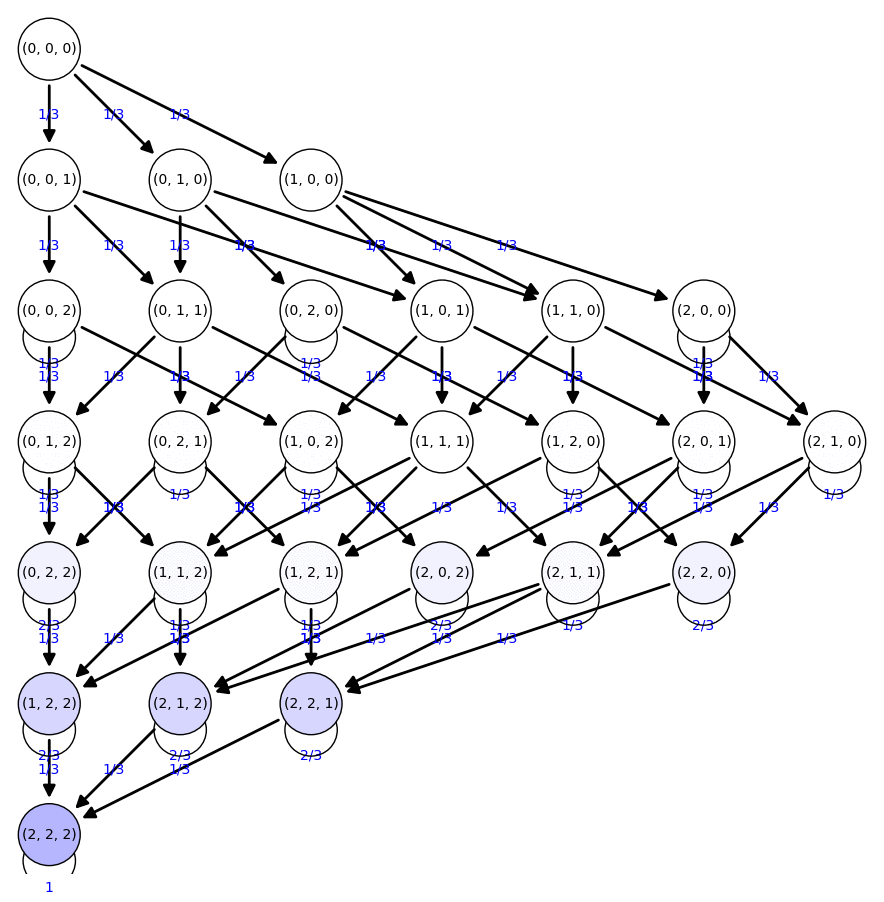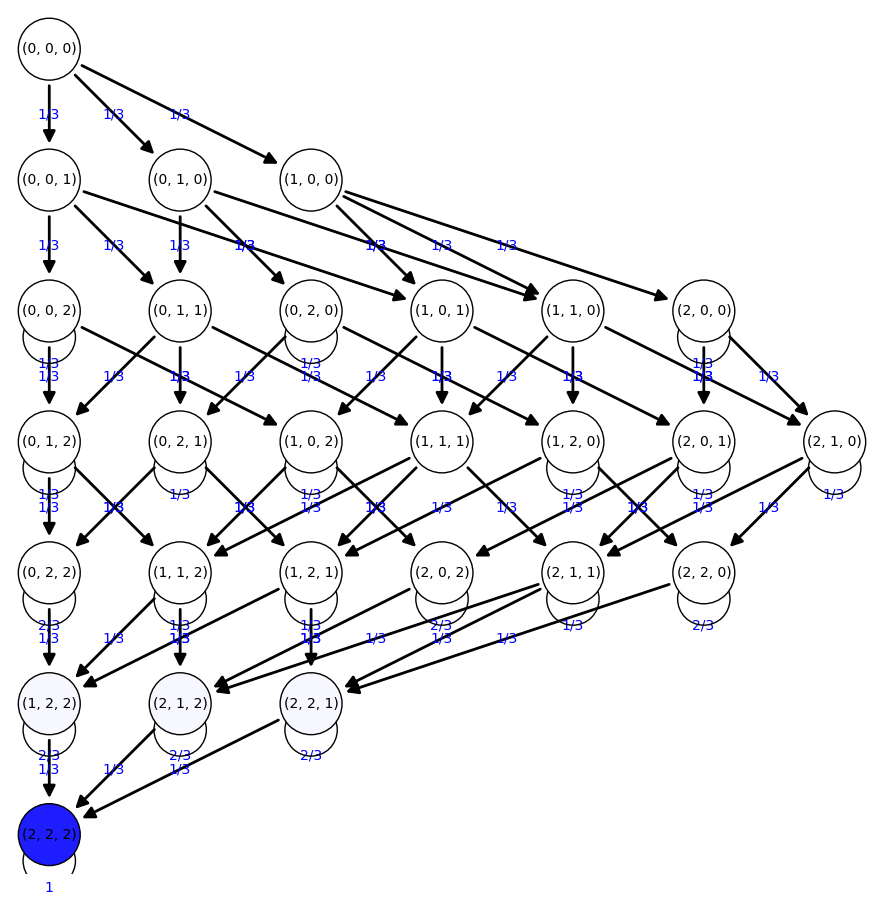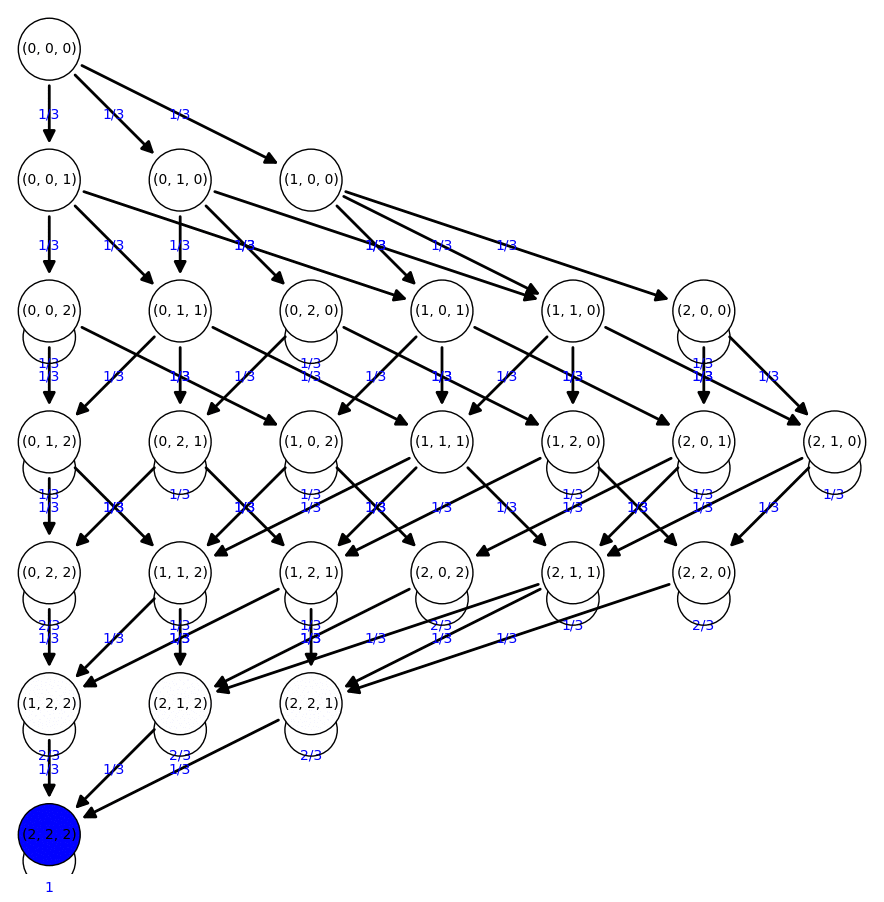
Paquetes de cereales
En una determinada marca de cereales, con cada paquete viene un regalo con las siguientes condiciones:
- Hay 2 regalos distintos
- Todos los regalos tienen la misma posibilidad de aparecer
Queremos saber cuántos paquetes tendremos que comprar para obtener dos veces cada regalo
|
|
[(0, 0, 0), (0, 0, 1), (0, 0, 2), (0, 1, 0), (0, 1, 1), (0, 1, 2), (0, 2, 0), (0, 2, 1), (0, 2, 2), (1, 0, 0), (1, 0, 1), (1, 0, 2), (1, 1, 0), (1, 1, 1), (1, 1, 2), (1, 2, 0), (1, 2, 1), (1, 2, 2), (2, 0, 0), (2, 0, 1), (2, 0, 2), (2, 1, 0), (2, 1, 1), (2, 1, 2), (2, 2, 0), (2, 2, 1), (2, 2, 2)] |
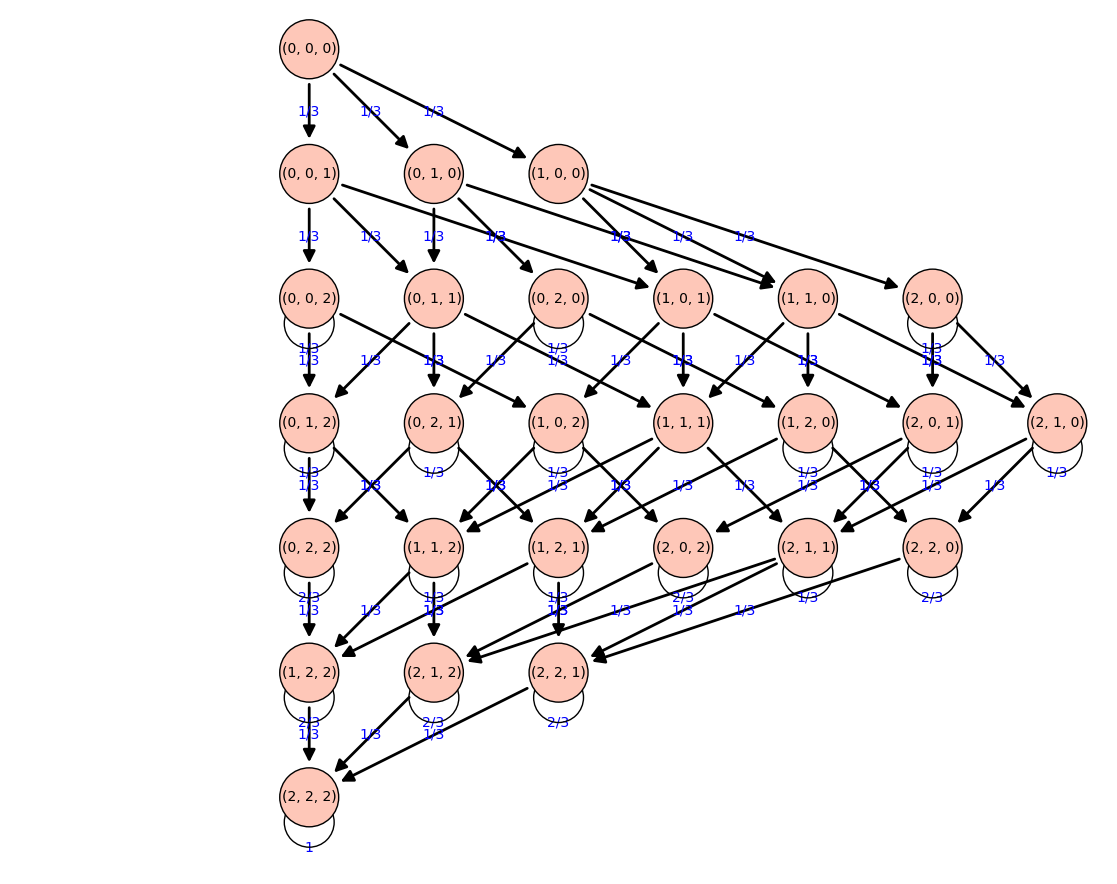
|
|
|
|
Tenemos de nuevo una cadena de Markov absorbente
Calculamos el tiempo medio en conseguir los regalos
Método de las ecuaciones:
Empleamos de nuevo el método de las ecuaciones sabiendo que:
- Partimos del primer vértice (0,0,0)
- Llegamos al último vértice (2,2,2)
Observamos la matriz del sistema:
|
(1−130−1300000−130000000000000000001−130−1300000−130000000000000000002300−1300000−130000000000000000001−130−1300000−130000000000000000001−130−1300000−130000000000000000002300−1300000−1300000000000000000023−130000000−1300000000000000000023−130000000−130000000000000000001300000000−130000000000000000001−130−1300000−130000000000000000001−130−1300000−130000000000000000002300−1300000−130000000000000000001−130−1300000−130000000000000000001−130−1300000−130000000000000000002300−1300000−1300000000000000000023−130000000−1300000000000000000023−130000000−130000000000000000001300000000−1300000000000000000023−130−1300000000000000000000000023−130−130000000000000000000000001300−1300000000000000000000000023−130−1300000000000000000000000023−130−130000000000000000000000001300−1300000000000000000000000013−130000000000000000000000000013−13000000000000000000000000001)
|
|
(1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0)
|
(0, 0, 0) : 347/36 |
|
|
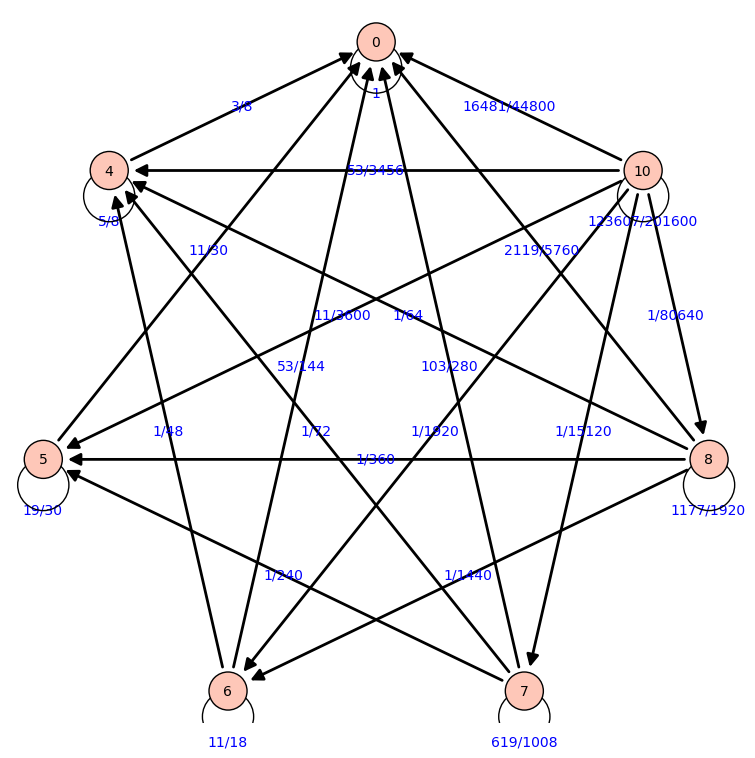
Permutación sin puntos fijos
Un grupo de amigos quieren hacer un regalo invisible, seleccionando los regalados de la siguiente forma:
- Cada amigo escoge un nombre al azar
- En caso de que haya coincidencias, se realiza lo siguiente
- Si coincide un único nombre, dos o tres, se reparten todos otra vez
- Si coinciden más, se reparten solamente aquellos que coincidan
Por otro lado, otro grupo de amigos (con el mismo número de personas que el anterior) realiza otro sorteo con las siguientes normas:
- Cada amigo escoge un nombre al azar
- En caso de que haya coincidencias, se reparten todos los nombres de nuevo
Queremos saber qué grupo acabará antes de repartir los nombres
|
|
GRUPO A
|
|
Otra forma de calcular las probabilidades:
{0: 16481/44800, 1: 16687/45360, 2: 2119/11520, 3: 103/1680, 4:
53/3456, 5: 11/3600, 6: 1/1920, 7: 1/15120, 8: 1/80640, 9: 0, 10:
123607/201600}
|
|
|
|
Los números representan las coincidencias. En el caso de 1, 2 o 3 coincidencias, vuelve directamente al nodo 10.
- pk(vk)=p(1 coincidencia)+p(2 coincidencias)+p(3 coincidencias)+p(k coincidencias)
pk(vk)=p(1 coincidencia)+p(2 coincidencias)+p(3 coincidencias)+p(k coincidencias)
|
(10000003858000001130019300000531441480111800010328017212400619100800211957601641360114400117719200164814480053345611360011920115120180640123607201600)
|
Calculamos la media mediante la matriz elevada a k
|
(10000000(1930)k0000000(58)k0000000(6191008)k0000000(123607201600)k0000000(11771920)k0000000(1118)k)
|
-1145/8954*(11/18)^k + 1145/8954*(11/18)^(k - 1) - 105065/1302444*(1177/1920)^k + 105065/1302444*(1177/1920)^(k - 1) + 23348506643631/33686935376116*(123607/201600)^k - 23348506643631/33686935376116*(123607/201600)^(k - 1) + 6960/205931*(619/1008)^k - 6960/205931*(619/1008)^(k - 1) - 1654425/1210858*(5/8)^k + 1654425/1210858*(5/8)^(k - 1) - 7027624/46224477*(19/30)^k + 7027624/46224477*(19/30)^(k - 1) |
Probabilidad total: 1 Media: 4714793176145/1735740376447 = 2.71630091695857 Varianza: 14015323199879059714359780/3012794654428373272343809 = 4.65193443545134 |
GRUPO B
Tenemos que, en este caso, se puede resolver el problema mediante las fórmulas de la media y la varianza de una distribución geométrica
Media = 44800/16481 = 2.71828165766640 Varianza = 1268691200/271623361 = 4.67077351273921 |
Obtenemos que, para 10 amigos, la diferencia es casi inapreciable, si bien el tiempo es mayor en el segundo caso.
|
|
Tartaglia
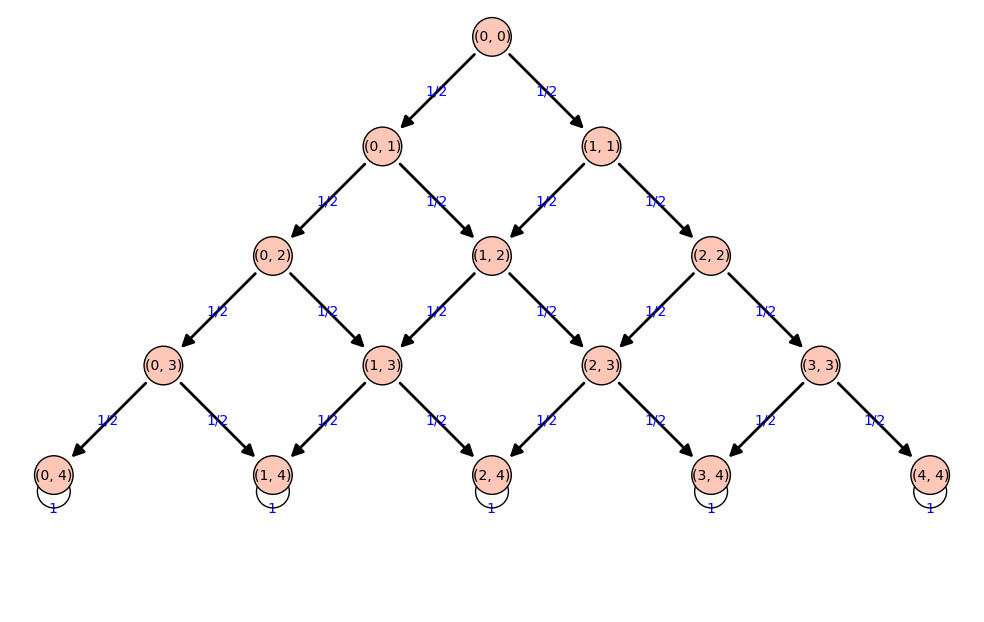
|
['(0, 0):1'] 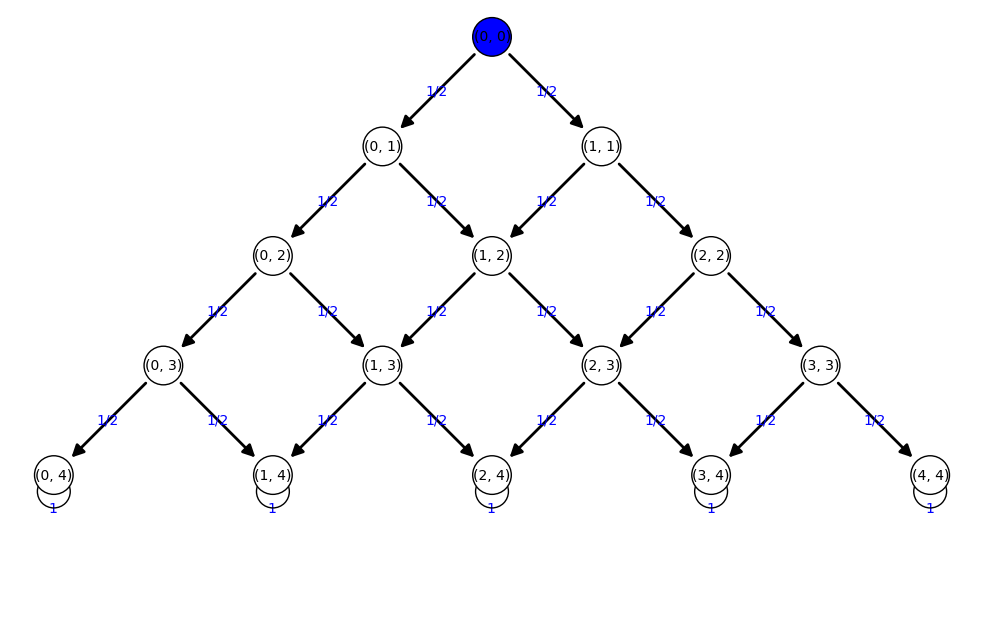 ['(0, 1):1/2', '(1, 1):1/2'] 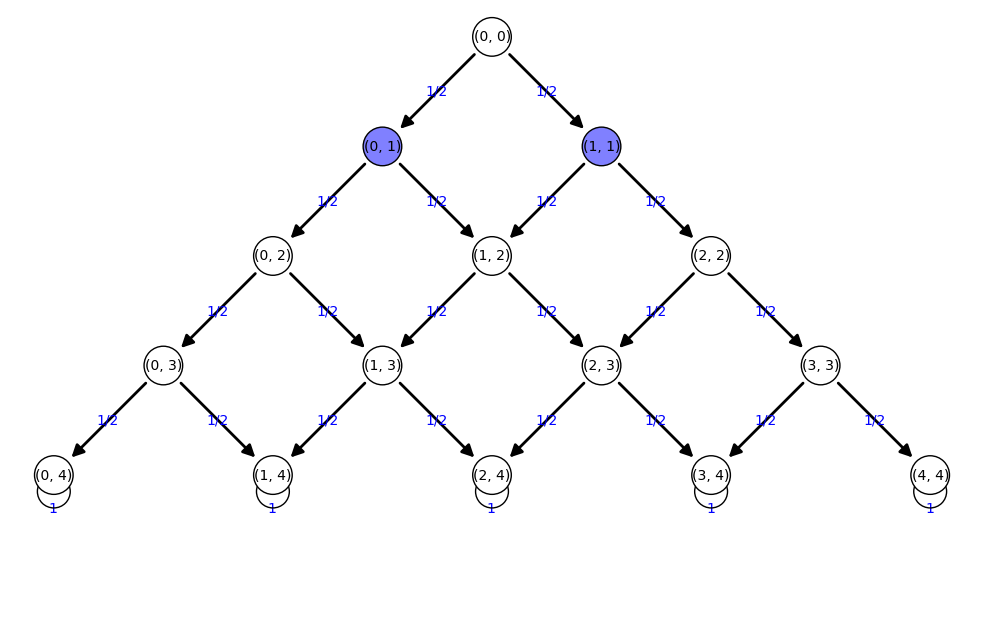 ['(0, 2):1/4', '(1, 2):1/2', '(2, 2):1/4'] 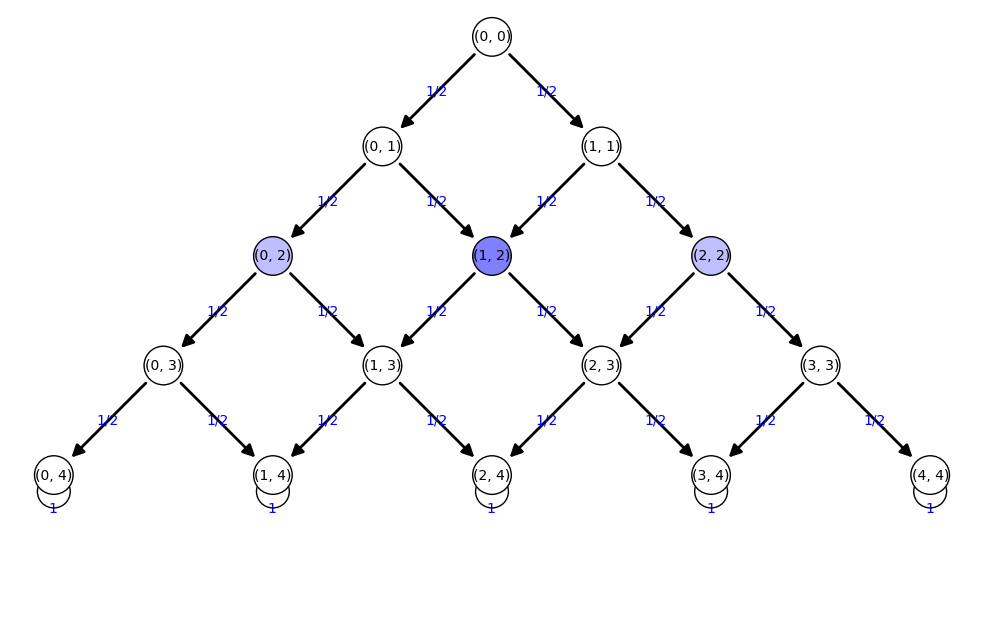 ['(0, 3):1/8', '(1, 3):3/8', '(2, 3):3/8', '(3, 3):1/8'] 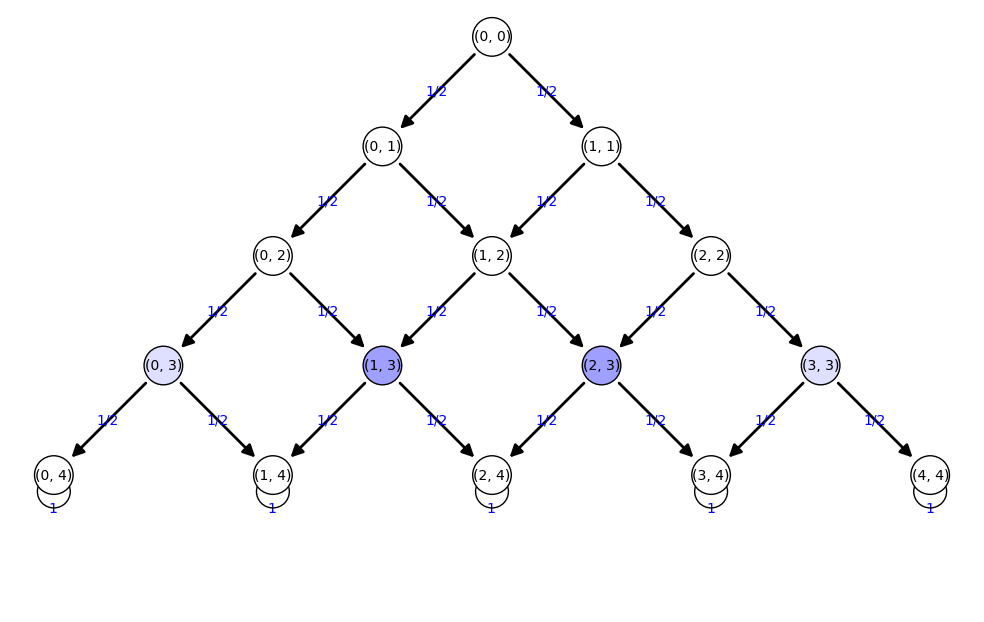 ['(0, 4):1/16', '(1, 4):1/4', '(2, 4):3/8', '(3, 4):1/4', '(4, 4):1/16'] 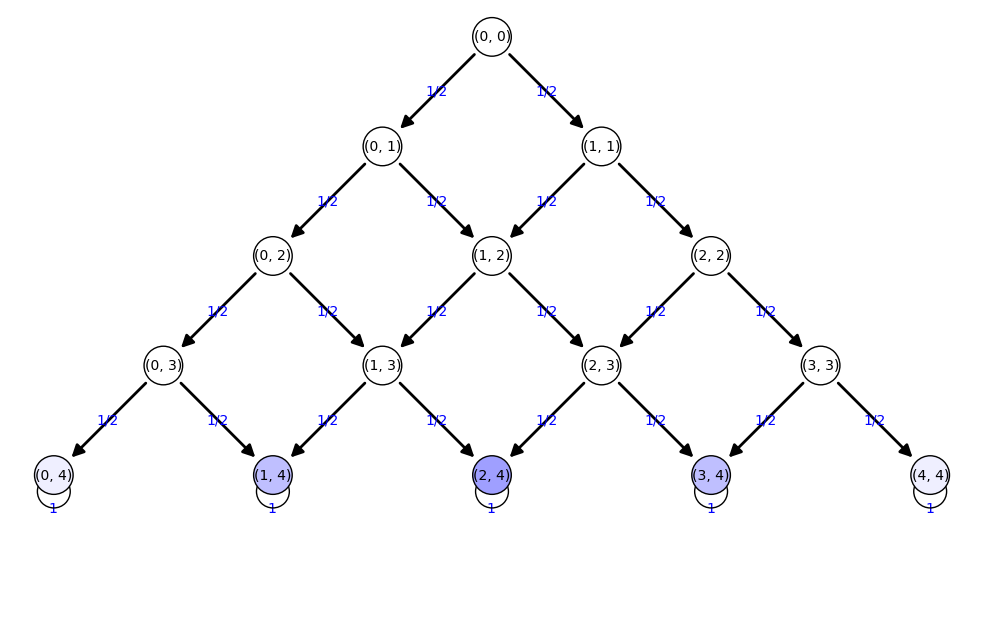 ['(0, 4):1/16', '(1, 4):1/4', '(2, 4):3/8', '(3, 4):1/4', '(4, 4):1/16'] 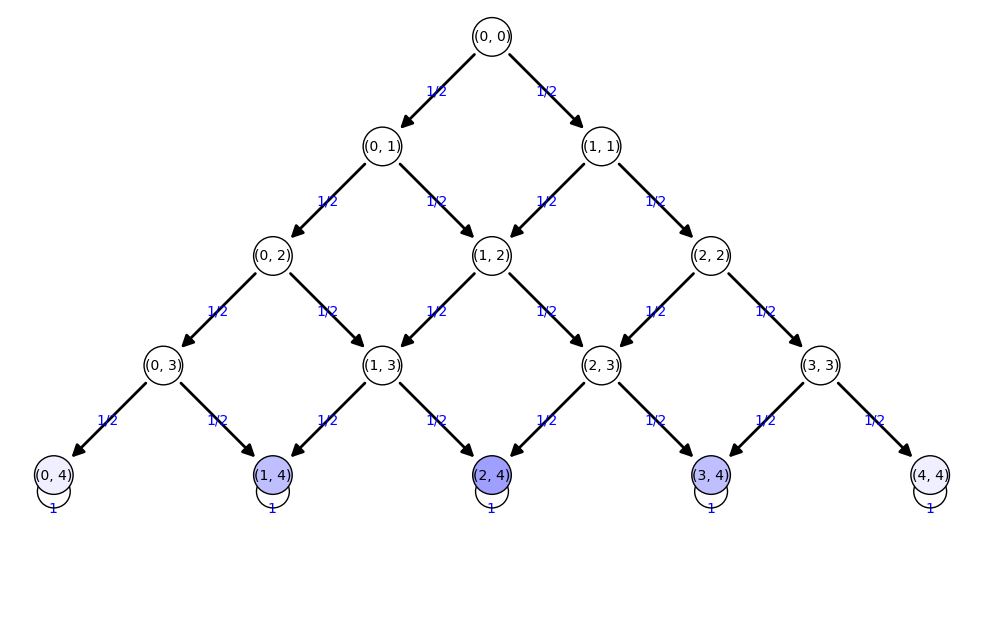
|
Tenemos que el tiempo en llegar al nivel inferior ¡es siempre 4!
La probabilidad estable se obtiene de la matriz M4
|
|
|
|
(0, 4) : 1/16 (1, 4) : 1/4 (2, 4) : 3/8 (3, 4) : 1/4 (4, 4) : 1/16 |
|
|
|
|
|
|
|
|
|
|